깃허브 모델은 놔두고 파인튜닝을 계속 하는 것으로 쓰인다. 이미지 생성시 추가 시간이 소요되지 않고, 파인튜닝 방식보다 결과 퀄리티가 좋으나 6GB이상의 CUDA 코어가 있어야 하는것으로 보인다.
-
Enhanced Super Resolution GAN 화질을 높여주는 업스케일러 계열 흐리게 한다음에 노이즈를 추가하여 업스케일된 이미지를 뽑아내는 방식으로, diffusion모델처럼 노이즈를 응용하여 그 가운데 화질을 높이는 방식을 채택
-
atrous convolution과 동의어.
연산량을 최대 3배까지 빠르게 할수 있는 업샘플링 방법이다. 출처 : FastFCN : Rethinking Dilated Convolution in the Backbone for Semantic Segmentation https://github.com/wuhuikai/FastFCN
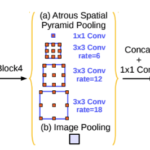
DeepLab V2에서 소개된 풀링 방법으로, 빈 공간을 둔 필터를 여러개 병렬로 나열해서 연산량을 줄이고 스케일에 강하게 만드는 풀링 방법. Atrous라는 말은 hole이라는 뜻이다. Atrous 컨볼루션은 연산량을 줄이고 최대한 넓은 영역까지 커버하기 위해서 몇가지의 점들만 이용해서 풀링하는 방법이다. 그리고 Spatial Pyramid Pooling은 이를 합치는 과정을 말한다. 공간에 대해 민감하게 반응해야하는점에서 알수 있듯이, 해당 공간을 표기해야하는 Semantic Segmentation분야에서 주로 쓰인다.
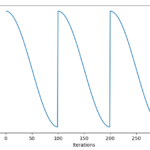
코사인 형태로 훈련비율(learning rate)을 차츰 조정하면서 좀더 정확도를 상승시킬수 있는 방법이다. learning rate은 계속해서 수렴해서 마른걸레를 짜다가, 다시한번 크게 가져가서 또다른 optima를 찾는 노력을 할수 있다. 훈련시, 오차와 정답의 차이를 100% 바로 반영해서 가중치를 수정하는게 아니라, learning rate으로 지정되어 있는 정도로 훈련이 진행된다. 이 숫자는 보통 0.01 부터 대충 0.000001 정도 까지의 다양한 수를 골라 이 값으로 훈련할 수도 있지만다. 하지만, 이를 계속 변경하면서 여러 최적점을 탐색하거나 fine tuning과 같이 좀더 나은 최적점을 향해 찾아가게 할수있다. 하나의 훈련양만 조절하는것보다, 코사인 어닐링을 이용하는 편이 좀더 에러를 줄어들게 하는걸 알수있다. 하나 더 추가적으로 보면 각각의 restart지점마다, 다른 모델이 튀어나올수도 있는데 이를 활용해서 앙상블로 정확도를 더 높일 수 있다. 각각의 지점에 대해서 잘 저장해두었다가 (checkpoint) 불러서 결과를 합산하는 방식도 존재 코사인 어닐링과 모델 체크포인트 앙상블 방법 실제로 모두 자주 볼수 있는 방법이지만, 코사인 어닐링은 1사이클만 훈련양을 낮춰가면서 해볼 수 있는 반면, 앙상블 방법은 여러 에폭을 돌려야 하기 때문에 시간이 오래걸려 feasibility만 보는 개발 단계에서는 시간제약이 있을 수 있다. 관련 논문 : SGDR: Stochastic Gradient Descent with Warm Restarts, Ilya Loshchilov, Frank Hutter / Snaptho ensembles : Tran1, Get M For Free
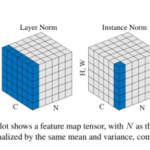
배치 정규화(표준화)와는 다른 방향으로 데이터를 표준화 작업을 거치는 방법. 한 채널 내의 데이터들을 적당한 수로 모아서(그룹별) 이를 표준화 작업을 거친다. Batch Normalization는 미니배치 N개를 기준으로 표준화 작업을 하지만, Group Normalization은 채널쪽의 데이터 일부(그룹)을 묶어 표준화 작업을 한다. 일반적으로 미니배치에서 표준화 작업을 거치는것보다는 미세하게 나은 정도지만, 강점은 배치수가 적을때에 있다. 해상도가 큰 이미지를 훈련하는 경우 시중에 나온 GPU로는 메모리가 터지는 경우가 존재한다. 또한 배치를 크게 줄수록 정확도가 미세하게 낮아지는 경우가 있어 부득이하게 배치를 10 이하로 낮추는 경우가 존재한다. 이렇게 적은 수의 배치를 돌려야 하는 경우가 많은데 이러한 경우에도 정해진 그룹안의 수에 맞춰서 표준화 작업을 하면 배치 Normalization의 이점을 누릴 수 있다. 해당 방법은 최근(2020년)에는 배치 노말라이제이션보다 정확도를 높여야 할 경우 고려되는 방법으로 모델링 시 자주 보인다. 그룹 노말라이제이션은 당연하게도 배치수에 별다른 차이를 받지 않는다. 관련 논문 : Group Normalization, Yuxin Wu, Kaiming He
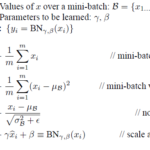
미니배치에서 (보통은) 활성화 함수전에 해당 데이터들을 모두 Z-score 와 유사한 방법으로 표준화 (Normalization) 함으로써 빠르게 수렴하고 강건(robust) 하게 만드는 방법이다. 결과적으로는 정확도 상승에 도움을 준다. 정확도 상승을 위해 거의 필수적으로 구현하고 있다. 잘 보면, 미니배치 대상의 평균과 분산을 더해 Z-score를 계산한다. epsilon은 분모 0 방지를 위한 미세한 값이며, 마지막에 감마와 베타로 다시 조정하기는 하지만, 여튼 Z-score에 기반한다. 관련 논문 : Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift, Sergey Ioffe, Christian Szegedy Normalization의 번역은 컨텍스트에 따라 다른데, 여기서는 Z-score와 유사한 방법으로 표준화를 하기 때문에 일반적인 L1, L2 regularization과 구분할수 있도록 표준화라 했다.

구글의 비공식 언어 라이브러리로써, 언어에 상관없이 비감독학습으로 문장을 토큰나이즈 (분석단위로 끊는것) 깃허브 : https://github.com/google/sentencepiece
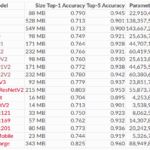
GPU로 제대로된 학습을 돌리기에는 많은 컴퓨팅 파워가 필요하므로, 이미 이론을 개발하거나 라이브러리를 개발하는 측에서 모델을 훈련해놓았다.https://github.com/keras-team/keras-applications/tree/master/keras_applications 위는 keras에서 사용할수 있는 기본적인 모델의 모델 사이즈와 벤치마킹 결과이다. 한가지 아쉬운점은 EfficientNet을 포함하고 있지 않는것인데, 최근의 어떤 벤치마킹은 다른곳에서 다룰 예정
-
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan, Quoc V.Le 2019다양한 Convolution Net들이 출현중인데 한가지의 공통점이 존재. 깊이를 깊게 하거나 넓이를 넓게 하거나 구조를 다양하게 해서 좀더 정확도가 높은 지점을 찾는다는것EfficientNet은 이 구조의 효율성을 찾아내 정확하게 예측력과 컴퓨팅파워를 절묘하게 균형을 맞춰서 SOTA를 달성구조가 복잡할수록 비례적으로 정확도는 증가하나 복잡도도 또한 증가.B0(빠름), B4(효율좋음), B7(예측력정확) 정도가 주로 쓰임 부분에서 효율적인 구조를 찾았기 때문에, 앞으로는 EfficientNet을 빼놓고 벤치를 논하기가 불가능할듯 하다.
-
U-net이나 Decoder의 경우 이미지의 크기를 역으로 키울 필요가 있다. 업 샘플링으로 14 -> 28로 변한것을 알수있다. UpSampling2D는 케라스 기준 내부적으로 resize_images() 를 호출한다. 즉, 적은 해상도를 일부러 고해상도로 올리는것이다. 단순히 잡아 늘리는 역할으로 바로 Conv2D의 함수가 호출되어야 될 필요가 있음Conv2DTranspose는 Convolution 연산이 들어가서 해상도를 키운다. 이 연산은 당연히 학습과정에서 필터가 학습이 된다. 보통은 H, W가 줄어들고 Feature map갯수에 따라 차원이 늘기 때문에 익숙한 개념은 아니지만, 패딩을 적당히 섞으면 H, W가 늘어나는것도 당연히 가능하다. 좀더 자세한 부분은 아래 출처 참조. https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
-
UNet++: A Nested U-Net Architecture for Medical Image Segmentation, Zongwei Zhou et al, 2018 Unet에서 Skip Path에 컨볼루션 레이어가 추가된 tuning된 형태의 네트워크Contracting path에서 Extracting path로 전달하는 feature map에 다시한번 여러 레이어를 추가함으로써 추가적인 예측률 확보Unet의 U자형 shape는 사실 Encoder – Decoder형태에 몇번의 스킵하는 커넥션이 있는 형태의 네트워크또한 스킵하는 커넥션은 결국은 Mask RCNN에서도 밝혀진 바와 같이, 예측률을 좋게 하는데 필수적. skip connection부분이 훨씬 많은 레이어로 강화되었다. 검정색은 오리지널 Unet, 그리고 초록색과 파랑색은 Skip path의 컨볼루션 레이어다. Skip Connection 부분에 위와같은 컨볼루션 블럭을 채워놓음으로써, 바로 전달되는것보다는 Feature map자체가 Decoder가 조금더 학습하기 좋게 전달Unet++의 위와같은 복잡한 네트워크는 Mask RCNN등에도 적용 가능, Unet++의 인코더에는 EfficientNet과 같은 백본도 이용 가능 네트워크의 인풋이 한두군데서 받는것이 아니기때문에 흡사 알고리즘 문제의 동적계획법을 보는듯이 짜여져 있다. H()는 컨볼루션 오퍼레이션, U는 업샘플링 레이어, []는 concat을 뜻한다. Unet++에는 이것만으로는 허전했는지 deep supervision이라는 방법을 끝단에 추가한다. 이는 출력값을 평균을 내서 예측률을 좀더 끌어올리고자 하는 것으로 보인다.
-
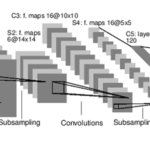
U자형 모형으로 되어있는 네트워크로, 의료영상 Segmentation 분야에서 비교적 높은 예측률을 보여옴.모델은 이미지의 컨텍스트를 학습하는 Contracting path과 정밀한 영역을 표시하기 위한 Expanding path로 나눠짐.둘은 서로 대칭관계 대칭형의 모양을 가진 u-net이지만, 사실은 평평하게 그려놓고 아치로 연결선을 표현한것과 다름이 없다. Contracting path는 3X3 컨볼루션과 ReLU, 그리고 2X2 Max Pooling, 그리고 2stride로 학습Expanding path는 2X2 컨볼루션인데 feature channel을 대신 절반으로 줄이는 연산을 함다만 Expanding path는 Contracting path에서 학습한 feature map을 그대로 붙여서 사용함 이전의 방식은 컨텍스트와 정밀한 영역간의 트레이드 오프가 있었으나, 이러한 방식으로 두마리 토끼를 동시에 잡음 학습 데이터가 많지않은 의료 데이터 특성을 반영을 잘 했기 때문에 비교적 적은 데이터로도 학습이 가능. 패딩을 하는 과정. 자세히 보면, 이미지가 복사되었음을 알수있음. 바운드에서 벗어나는 곳 경계선은 다른 부분을 그대로 복사하여 사진 가운데로 느끼게끔 보충 weight map을 통해 경계선에 대한 가중치를 줘서 구별이 더 잘되게 함, 셀들을 골라내는 작업도 중요한 분야가 있기 때문에 이러한 경우에는 weight map으로 보정다만 병변범위가 구별될 필요는 없는경우 위와같은 과정이 필요없을 수 있음이미지를 나눠서 그리드별로 섞는 등의 적당한 데이터 어그멘테이션도 진행이 되었다고 언급. 마지막의 드랍아웃 레이어도 간접적인 어그멘테이션이 진행되었다고 하ㅓㄹ수있음 논문과 대회를 우승한 시기는 2015년으로, 다소 연식이 된 편이며, Unet++등으로 발전 우승한 ISBI 2015의 경우, Intersecotion Over Union 기준 우승을 차지. 논문 마지막에는 Nvidia Titan GPU (6G)로 단지(?) 10시간정도의 학습소요시간이 걸렸다고 언급.
-
기본적으로 제공되는 feature importance는 보통 가지에서 몇번 등장하는지, 혹은 불순도를 얼마나 낮추는 지에 대한 지표이다. 이러한, 방법의 문제점은 -영향을 주는 feature를 알수 없다는 것이다.순열 특성 중요도는 답이 있는 test set에 대해서, 혹은 validation set에 대해서 한번에 한개씩 feature를 선택한다음 해당하는 값들을 죄다 의미없는 값(value)들로 바꿔버린다.비슷한 방법으로 Leave one feature out방법이 있지만, 해당 feature를 제외한채 훈련을 해야하기 때문에 훨씬 자원소모적이다.
-
Pierre Geurts, Extremely Randomized Tree, 2005랜덤 포레스트보다 랜덤화된 요소를 가지고 있는 트리트리 분기 시 컷포인트(cut-point)를 찾을때 이를 랜덤으로 결정분류문제는 투표로, 회귀문제는 평균으로 결과치를 산출.논문상 랜덤 포레스트보다 미세하기 앞서며, 노이즈 데이터에 대해서는 결과는 랜덤포레스트와 비슷하다는 제보. Draw a random cut-point 라고 되어있는 부분이 핵심. 사용자들의 이해도가 높지는 않아 단일로는 잘 쓰이지 않으며, 각종 대회등에서 앙상블 용으로 많이 이용.분기되는 지점을 랜덤으로 선택하기 때문에 훈련속도가 랜덤 포레스트보다 약 세배정도 빠른편으로, Scikit-Learn에 구현이 되어있음. PST – Pruned Single Tree, TB – Tree Bagging, RS – Random Subspace, RF – Random Forests 단일트리모델을 제외하고는, 앙상블 모델끼리의 유의할만한 차이는 보기 힘들다는 판단

David Duvenaud et al. ,Convolutional Networks on Graphs for Learning Molecular Fingerprints, 2015graph를 이용한 분자단위의 예측은 화학 분야에서 이용도가 높은데 이를 컨볼루션 네트워크를 이용하여 구성기존의 방식과 컨볼루션 네트워크를 이용한 방식의 알고리즘적인 차이는 아래와 같음 참고자료 https://arxiv.org/pdf/1812.08434.pdf

Graph Neural Network의 일종으로, 텍스트분석과 같은 경우처럼 맥락을 통해 비교사 학습을 통한 임베딩을 산출Word2Vec의 대표적인 방법인 Skip-gram을 이용해서 그래프를 표현그래프가 계속 바뀌면 계속적인 훈련 필요
-
화학구조물 같은 그래프를 다룰 때의 신경망 모델노드(node)와 간선(edge)이 있는 그래프에서 노드가 무엇에 해당하는지 알기 위함이 기본노드는 서로 연결되어 있으므로, 이를 맞추기 위해서 정보를 얻을수 있는것들이 있으며, 간단히 아래와 같은 식으로 표현 좌항이 노드임베딩이라면, f()안의 변수는 차례대로 노드피처, 엣지피처, 이웃노드임베딩, 이웃노드피처 기본적인 머신러닝과 다른점은 x만 있는것이 아니고, 구조적으로 이웃노드와 엣지로부터의 정보도 이용할수 있다는 점.

분산이 같지 않는 상태에서 두 샘플이 서로 평균이 다른지 확인하는 방법Student’s t-test 는 분산이 같다고 가정한다.

Gao Huang, Snapshot Ensembles: Train 1, get M for freePavel Izmailov, Averaging Weights Leads to Wider Optima and Better Generalization, 2019 신경망 모델 다수를 앙상블링 하는 방법은 대회등에서 꾸준히 정확도를 높이기 위해 사용되어왔던 방법다수의 여러개의 모델을 만들기 위해서는 하나를 만들때보다 N배의 컴퓨팅 자원 필요. 이를 효율적으로 학습하고자 한번의 학습으로만 다양한 모델을 반영하도록 유도Snapshot Ensembling – SGD가 local optima (국소최적화) 지점을 찾기위해 계속 공간을 돌아다니도록 하고, 이를 반복하여 다양한 가중치들을 찾고, 이를 평균냄Fast Geometric Ensembling (FGE) – 훈련율 (learning rate)를 consine대신 linear하게 설정하여 조금더 빠르게 학습이 될수 있도록 함. 여러 골짜기(local optima)들이 중간중간 박혀있는 것이 아니라, 보통은 계곡이 계속되기 때문SWA에서는 굳이 여러 모델들의 파라미터를 가지고 있지않고, 프로그래밍에서 값을 업데이트 하는 것처럼 weight를 업데이트 한 다음, 최종적으로 돌때는 이미 업데이트가 되어있는 방식 여러개의 국소값들을 찾아 이를 합치는 방식 (Snapshot Ensembling) 실질적인 국소 최적화 지점 (Fast Geometric Ensembling) Stochastic Weight Averagin 에서 한번씩 값을 업데이트 하는 방법
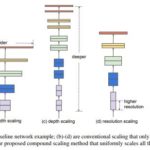
현재 트렌드로는 다양한 합성곱 신경방등이 넓이(width), 깊이(depth), 해상도(resolution) 등의 여러가지 다양한 특성으로 합성곱 신경망 모델을 구성depth – resnet같은 경우를 예로 들면, 깊이에 따라 정확도가 높아짐 (일정이상은 높아지지 않고, 1000이상이면 무용지물)width – 여러가지 filter를 적용하여 width가 길어진 네트워크는 많은 fine-grain feature를 훈련할수 있음. 다만 너무 깊이가 얕으면 추상적레벨의 feature를 반영하지 못할 수는 있음.resolution – 당연히 해상도가 높아지면 정확도가 높아지지만, 600X600정도 이상이면 정확도 상승폭에 비해 하드웨어 무리결국 정확도 상승을 위해 극한의 하드웨어 성능이 필요한 정도로 모델이 커지지만, 상승폭은 계속 줄어들게 됨.이 셋의 밸런스를 잘 맞추는것이 제일 가성비(?)가 좋은 네트워크를 만들게 됨.따라서 Efficient Net은 메모리, CPU에 따라 제일 좋은 효과를 얻을 수있는 공식을 찾아내기 시작 효과는 다음과 같이, 적은 자원으로도 State of the art 를 뛰어넘는 높은 정확도를 달성할수 있음을 보임

테스트 데이터에 대해 어그멘테이션을 적용다양하게 뒤틀려있는 테스트 데이터를 예측하고 이를 평균내어 원본 테스트 데이터에 대해 최종 예측
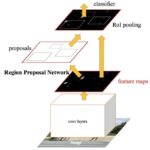
Shaoqing Ren, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016Selective Search를 제거하고, Region Proposal Network(RPN) 도입하여 속도를 최상으로 높인 물체 검출기 RPN + Fast RCNN으로, 동일한 feature를 이용함.VGG16으로 5FPS를 달성

Mask R-CNN, Kaiming He, 2018바운딩박스와 이미지 예측뿐만아니라 픽셀마다 해당 물체에 속하는지 마스킹까지 해주는 방식 (Instance Segmentation)기본구조 Faster-RCNN까지 같고, 이에 마스킹 레이어까지 추가출력이 두개(분류, 바운딩박스) 에서 K*m*m mask 출력 추가 세 프로세스는 병렬로 이루어짐각각의 Proposal의 픽셀에 대해 하나하나 마스킹 이진 분류기존의 방법은 픽셀당 멀티클래스 분류Faster-RCNN에서 RoIPool로 뭉개진 원본 픽셀 정보를 RoIAlign으로 원본에서의 위치를 유추RoIPooling시 원본 이미지와 stride를 통한 RoI가 정확히 나눠지지 않아 소수점을 버리는데(quantization) 이를 개선하기 위한 보간법 이용.Loss Function은 L(cls) + L(box) + L(mask)로 이루어짐마스크의 경우 해당 분류의 마스크만 이진 크로스 엔트로피로 계산ResnetXt101-FPN(Feature Pyramid Network) 방식의 백본이 정확도가 가장 높음속도는 5FPS(Frame per second)으로 실시간 검출 가능사람 포즈 검출도 중요 키포인트에 마스킹을 하는것으로 구조 이용 가능. RoIAlign을 통해 마스킹을 하는 방법을 소개한 Mask RCNN RoIAlign을 통해 보간하는 방법 헤드 구조 averaged over IoU thresholds 벤치마킹
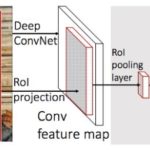
Ross Girchick, Fast R-CNN, 2015단일의 CNN만을 훈련하여 R-CNN의 속도를 개선함 (약 9배)간단한 절차는 아래와 같음대상이미지의 feature map을 필터로부터 산출RoI Pooling Layer – Region 후보군들을 설명하는 고정길이의 feature vector를 feature map으로부터 산출. 이를 완전 연결 신경망으로 전달해 Bounding Box와 멀티클래스 분류를 하게됨 (SVM보다 FC -> softmax선호) Fast R-CNN의 구조, RoI풀링 레이어가 추가됨
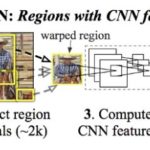
Ross Girshick, Region-based Convolutional Networks for Accurate Object Detection and Segmentation, 2015최대한 그림을 분할 후, 이를 가까운 분할별로 통합하는 작업 (Selective Search)를 통해 ~2000개의 후보 Region을 산출분할별 통합에는 shape, texture, color, size별로 유사도 계산각각의 Region별로 CNN을 적용하여 feature 추출 후 멀티클래스 분류Bounding Box에는 회귀방법이, 최종 예측은 SVM(Support Vector Machine)방법 적용 논문에서 제시하는 분류결과 논문에서 제시하는 분류 정확도

Navneet Dalal, Histograms of Oriented Gradients for Human Detection, 2015대상 영역을 일정 크기의 셀로 분할중요한 픽셀의 방향 히스토그램 계산 후 일렬로 벡터화윤곽선등으로 물체를 식별할 수 있을 경우 적합 Disclaimer ! 딥러닝이 대두하기 전의 기법

Lowe. D. G (Distinctive Image Feature from Scale-Invariant Keypoints, 2004)시점 : 1997~이미지와 크기와 회전에 불변하는 특징을 추출하는 알고리즘.스케일이 축소된 일련의 이미지들 (이미지 피라미드) 에서 동일하게 검출되는 Scale Invariant 한 Feature 추출코너성을 측정하기 위해서는 DoG(Difference of Gaussian) 을 이용하여 스케일별 Laplacian 계산특징점이 풍부한 경우에 유리 키포인트 셀렉션 단계 스케일이 작거나, 커도 모두 검출 Disclaimer ! 딥러닝이 대두하기 전의 기법
-
바운딩 박스는 아래처럼 물체를 감싸는 박스를 나타낸다. 예쁘게 잘 감싸줘야 필요한 정보만 가지고 잘 판단할수 있을것이다. x, y는 박스의 좌표를 말하며, w와 h는 너비와 높이를 뜻한다.다만 w와 h는 로그로 한번 감싸여져 있다. Groundtruth가 있을 경우, 이를통해 Proposal과 비교하면서 서서히 위의 수치들을 맞춰갈수 있다. 따라서 바운딩박스를 맞추는 문제 또한 수치를 적합하는 회귀문제 # 참고자료 https://www.slideshare.net/aurot/auro-tripathy-localizing-with-cnns
-
SGD : Stochastic Gradient Descent, 조금씩 기울기를 수정해나가는 방식으로, 기본에 속하지만 방향이 다른경우 기울기가 달라져 탐색경로가 비효율적. 속도가 후에 나온 옵티마이저보다 훨씬 느린편임.Momentum : SGD에 가속변수를 하나 추가하여 탐색이 가속적AdaGrad : 개별 매개변수에 적응적으로 학습률을 조정하면서 학습을 진행. 즉 초반에는 빠르다가 점차 감소해가면서 갱신해감RMSProp : 지수 이동평균을 이용해(Exponential Moving Average)초반 기울기보다는 최근의 기울기 정보를 반영해감.Adam : 모멘텀과 AdaGrad의 장점을 취한 방법으로 편향 보정이 진행 참고 및 시각화 출처 https://github.com/Jaewan-Yun/optimizer-visualization https://emiliendupont.github.io/2018/01/24/optimization-visualization/
-
이미지등의 Segmentation 에서 쓰이는 지표영상 이미지등에서 정답과 예측값간의 차이를 알기위해 쓴다. 무슨 축약된 단어는 아니고 사람이름이다. Sørensen–Dice coefficient 라고도 하며, F1 Score와 개념상 같지만, 영상처리에서 더 강조를 하는 경향이 있다.라벨링된 영역과 예측한 영역이 정확히 같다면, 1이되며 그렇지 않을 경우에는 0이 된다. 아래와 같이도 표현한다 F1은 알다시피, 리콜과 정밀도의 조화평균이다. 즉, 두개다 동시에 고려하는 조화로운 지표라는 것이다.
-
Classification – 해당 사진이 특정 물체를 나타내는지 판별Localization – 해당 사진중 우리가 집중하고자 하는 부분을 골라냄Object Detection – 사진에 보이는 해당 물체들을 각각 골라냄Semantic Segmentation – 의미대로 사진 분할 (픽셀분류)Instance Segmentation – 객체대로 사진 분할 (픽셀분류)
-
AAAABBCC와 같이 중복되는 코딩에서는 A4B2C2와같이 압축하는 기법을 뜻한다.
-
sklearn.metrics 라이브러리를 까보면, 흔히쓰는 R스퀘어 (결정계수)말고도 비슷한 개념의 metrics가 한개가 더있다. 바로 설명분산점수(Explained Variance Score)인데 사실 R제곱 자체가 1 – (Sum of Squared Residuals / Total Variance) 로 정의되어있기 때문에, 이게 도대체 뭔 측정도구인지 싶을때가 있다. 코드를 까보면 아래와같이 설정되어있다.Explained Variance Score = 1 – ( (Sum of Squared Residuals – Mean Error) / Total Variance ) 유일한 차이는 SSR에 Mean Error를 뺀다는것이다. 만약 모델이 얼추 제대로 맞추고 모델에서 나오는 오차는 별 트렌드없이 0을 기준으로 왔다갔다 한다면 둘의 값은 거의 비슷할것이다. 다만, 에러가 한쪽에 쏠려 있다거나 한다면 일단은 모델이 좀 편향되게 (잘못) 피팅이 되었다는 것이고 이는 Mean Error가 0에 가까운 값이 아닌 – 나 +를 띄게 된다. R제곱과 설명분산점수가 다르게 나온다면 에러에 편향이 있다는것이고, 피팅이 잘못되었다는것을 뜻한다.굳이 부각되지 않은것은 어차피 잔차에 편향이 존재하지 않아야 회귀분석이 제대로 이뤄진것을 가정하기 때문이다. 직관적으로 이해하자면, 설명분산점수는 결정계수와 다르게 경향성도 제거하기 때문에 눈꼽만큼 나은 지표지만, 실질적인 이득은 없어보인다.
-
Fine-Tuning 새로운 데이터로 다시한번 가중치를 세밀하게 조정하도록 학습. 기존 데이터는 기존대로 분류Feature Extraction기존 가중치는 그대로 놔둔뒤, 새로운 레이어를 추가해서 이를 학습하고 최종 결과를 내게끔 학습Joint Training새로운 데이터를 추가하여 처음부터 다시 시작Learning without Forgetting새로운 데이터로 가중치를 세밀하게 조정하되, 기존 데이터 분류 결과 또한 개선 가능(하다고 주장) Li, Zhizhong, and Derek Hoiem. “Learning without forgetting.” In European Conference on Computer Vision, pp. 614-629. Springer International Publishing, 2016. https://arxiv.org/abs/1606.09282
-
데이터를 고유값(의 제곱근)으로 나누어 정규화 시키는 방법데이터의 분포를 고르게 깨끗하게 만드는것으로 이해하면 된다. 아래의 프로세스1) 평균차감을 통해 평균을 0으로 만들고2) PCA를 통해 데이터간 상관관계를 없애고3) Whitening을 통해 분산을 1로 만든다.보통은 예측력이 미세하게나마 좋아진다.
-
보통은 이미지 처리에서, 훈련할수 있게 라벨링하는것을 뜻함이미지 처리에서는 단순 라벨링 뿐만 아니라 boxing등도 필요하기 때문에, 이를 세세하게 annotate하는것이 필요함상당히 지루하나 중요한 과정이기 때문에 관련 annotatation 작업을 하는 회사도 존재.데이터 주석화라는 말은 현재 한국말에서 통용되고 있지 않지만, Data Annotation은 이미지 처리에서는 기본적인 단어
-
범주형 변수가 그룹마다 빈도가 다른지 확인하는 방법남자중 게이 비율 <-> 여자중 레즈비언의 빈도 차이가 있는지 물음에 답할수있음ANOVA와의 차이점은 수치형 <-> 명목형
-
T-test는 2집단 까지 차이 비교가 가능남/여 식욕차이Anova는 3집단 이상 차이 비교 가능남/여/트랜스젠더 식욕차이L/G/B/T 식욕차이
사전
Recent Posts