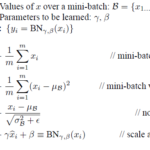Machine & Apps. Start Building.
깃허브 모델은 놔두고 파인튜닝을 계속 하는 것으로 쓰인다. 이미지 생성시 추가 시간이 소요되지 않고, 파인튜닝 …
Enhanced Super Resolution GAN 화질을 높여주는 업스케일러 계열 흐리게 한다음에 노이즈를 추가하여 업스케일된 이미지를 뽑아내는 …
atrous convolution과 동의어.
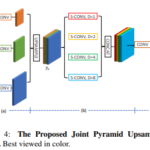
연산량을 최대 3배까지 빠르게 할수 있는 업샘플링 방법이다. 출처 : FastFCN : Rethinking Dilated Convolution …
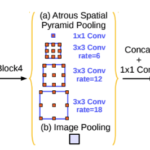
DeepLab V2에서 소개된 풀링 방법으로, 빈 공간을 둔 필터를 여러개 병렬로 나열해서 연산량을 줄이고 스케일에 …
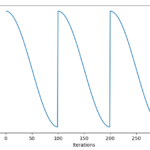
코사인 형태로 훈련비율(learning rate)을 차츰 조정하면서 좀더 정확도를 상승시킬수 있는 방법이다. learning rate은 계속해서 수렴해서 …
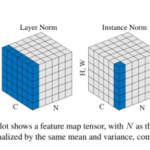
배치 정규화(표준화)와는 다른 방향으로 데이터를 표준화 작업을 거치는 방법. 한 채널 내의 데이터들을 적당한 수로 …
미니배치에서 (보통은) 활성화 함수전에 해당 데이터들을 모두 Z-score 와 유사한 방법으로 표준화 (Normalization) 함으로써 빠르게 …
구글의 비공식 언어 라이브러리로써, 언어에 상관없이 비감독학습으로 문장을 토큰나이즈 (분석단위로 끊는것) 깃허브 : https://github.com/google/sentencepiece
GPU로 제대로된 학습을 돌리기에는 많은 컴퓨팅 파워가 필요하므로, 이미 이론을 개발하거나 라이브러리를 개발하는 측에서 모델을 …
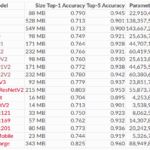
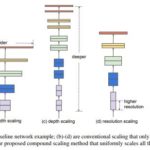
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan, Quoc V.Le 2019다양한 Convolution Net들이 …
U-net이나 Decoder의 경우 이미지의 크기를 역으로 키울 필요가 있다. 업 샘플링으로 14 -> 28로 변한것을 …
UNet++: A Nested U-Net Architecture for Medical Image Segmentation, Zongwei Zhou et al, 2018 Unet에서 …
U자형 모형으로 되어있는 네트워크로, 의료영상 Segmentation 분야에서 비교적 높은 예측률을 보여옴.모델은 이미지의 컨텍스트를 학습하는 Contracting …
기본적으로 제공되는 feature importance는 보통 가지에서 몇번 등장하는지, 혹은 불순도를 얼마나 낮추는 지에 대한 지표이다. …
Pierre Geurts, Extremely Randomized Tree, 2005랜덤 포레스트보다 랜덤화된 요소를 가지고 있는 트리트리 분기 시 컷포인트(cut-point)를 …
David Duvenaud et al. ,Convolutional Networks on Graphs for Learning Molecular Fingerprints, 2015graph를 이용한 분자단위의 …
Graph Neural Network의 일종으로, 텍스트분석과 같은 경우처럼 맥락을 통해 비교사 학습을 통한 임베딩을 산출Word2Vec의 대표적인 …
화학구조물 같은 그래프를 다룰 때의 신경망 모델노드(node)와 간선(edge)이 있는 그래프에서 노드가 무엇에 해당하는지 알기 위함이 …
분산이 같지 않는 상태에서 두 샘플이 서로 평균이 다른지 확인하는 방법Student’s t-test 는 분산이 같다고 …
Gao Huang, Snapshot Ensembles: Train 1, get M for freePavel Izmailov, Averaging Weights Leads to …
현재 트렌드로는 다양한 합성곱 신경방등이 넓이(width), 깊이(depth), 해상도(resolution) 등의 여러가지 다양한 특성으로 합성곱 신경망 모델을 …
테스트 데이터에 대해 어그멘테이션을 적용다양하게 뒤틀려있는 테스트 데이터를 예측하고 이를 평균내어 원본 테스트 데이터에 대해 …
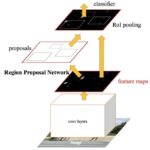
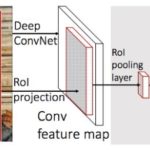
Shaoqing Ren, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016Selective Search를 제거하고, …
Mask R-CNN, Kaiming He, 2018바운딩박스와 이미지 예측뿐만아니라 픽셀마다 해당 물체에 속하는지 마스킹까지 해주는 방식 (Instance …
Ross Girchick, Fast R-CNN, 2015단일의 CNN만을 훈련하여 R-CNN의 속도를 개선함 (약 9배)간단한 절차는 아래와 같음대상이미지의 …
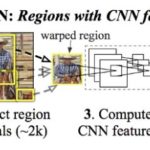
Ross Girshick, Region-based Convolutional Networks for Accurate Object Detection and Segmentation, 2015최대한 그림을 분할 후, …
Navneet Dalal, Histograms of Oriented Gradients for Human Detection, 2015대상 영역을 일정 크기의 셀로 분할중요한 …
Lowe. D. G (Distinctive Image Feature from Scale-Invariant Keypoints, 2004)시점 : 1997~이미지와 크기와 회전에 불변하는 …
바운딩 박스는 아래처럼 물체를 감싸는 박스를 나타낸다. 예쁘게 잘 감싸줘야 필요한 정보만 가지고 잘 판단할수 …
SGD : Stochastic Gradient Descent, 조금씩 기울기를 수정해나가는 방식으로, 기본에 속하지만 방향이 다른경우 기울기가 달라져 …
이미지등의 Segmentation 에서 쓰이는 지표영상 이미지등에서 정답과 예측값간의 차이를 알기위해 쓴다. 무슨 축약된 단어는 아니고 …
Classification – 해당 사진이 특정 물체를 나타내는지 판별Localization – 해당 사진중 우리가 집중하고자 하는 부분을 …
AAAABBCC와 같이 중복되는 코딩에서는 A4B2C2와같이 압축하는 기법을 뜻한다.
sklearn.metrics 라이브러리를 까보면, 흔히쓰는 R스퀘어 (결정계수)말고도 비슷한 개념의 metrics가 한개가 더있다. 바로 설명분산점수(Explained Variance Score)인데 …
Fine-Tuning 새로운 데이터로 다시한번 가중치를 세밀하게 조정하도록 학습. 기존 데이터는 기존대로 분류Feature Extraction기존 가중치는 그대로 …
데이터를 고유값(의 제곱근)으로 나누어 정규화 시키는 방법데이터의 분포를 고르게 깨끗하게 만드는것으로 이해하면 된다. 아래의 프로세스1) …
보통은 이미지 처리에서, 훈련할수 있게 라벨링하는것을 뜻함이미지 처리에서는 단순 라벨링 뿐만 아니라 boxing등도 필요하기 때문에, …
범주형 변수가 그룹마다 빈도가 다른지 확인하는 방법남자중 게이 비율 <-> 여자중 레즈비언의 빈도 차이가 있는지 …
T-test는 2집단 까지 차이 비교가 가능남/여 식욕차이Anova는 3집단 이상 차이 비교 가능남/여/트랜스젠더 식욕차이L/G/B/T 식욕차이
입력게이트, 출력게이트, 망각게이트등을 이용해 그라디언트 소실 문제를 극복하고 맥락을 잘 보존하게끔 하는 신경망 방법론텍스트분석처럼 앞뒤의 …
신경망을 훈련할때, 최종 출력에서 멀어질수록 값에 영향을 미치는값을 역산하여야 하는데, 거슬러올라가다보면 영향을 미치는 정도가 굉장히 …
과거의 출력이 다시 입력이 되는 구조순환신경망 (Recurrent Neural Network)에서 쓰이며, 기억저장소 같은 역할을 함 연속성이 …
앞단의 Convolution 레이어는 필요에 의해 일부만 연결되어있다고 할 수 있다. (이미지 픽셀 하나하나마다 연결되어있으면 쓸데없는 …
Gradient Descent를 실행하고 모델의 가중치를 갱신할때 고려할 데이터의 갯수다.배치 크기가 1이라면 Stochastic Gradient Descent가 된다. …