이글의 최종적인 목적은 BERT의 이해에 있습니다. 요즘 텍스트분야도 또한 발전이 빠르고, 구글놈 아니 구글분들을 비롯하여 똑똑이들의 경연장이 된것 같습니다.
그 와중에, 한국말과 같은 다양한 언어까지 지원할수 있도록 여러 언어에 대해서 미리 훈련된 모델(Pretrained Model)을 구글분들이 만들어놓으셨으니, 참 이로운 세상이지요.
Seq2Seq Model
Seq2Seq모델은, 문장을 순서대로 처리합니다. 문장은 단어의 순차적인 조합에 의해 이루어져있는데, 적당한 토큰을 나눠 이를 차례대로 마법의 상자인 Seq2Seq model에 넣습니다. 마법의 상자에서는 하나의 단어를 넣으면, 이의 컨텍스트 (맥락)을 뜻하는 벡터 하나가 튀어나오며, 다시한번 다음단어를 이 맥락벡터와 함께 넣으면 그 단어의 의미를 포함하는 맥락 벡터 2로 튀어나옵니다. 그래서 모든 단어를 집어넣고 최종적인 맥락벡터N을 받고 이를 다시 디코딩을 하든지 튀겨먹든지 하면 되는것입니다.
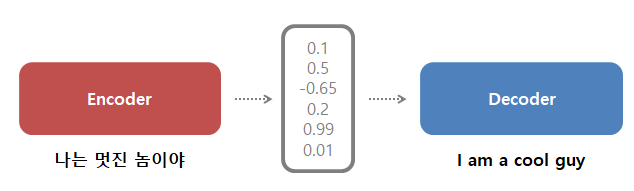
다만, 차례차례 토큰(단어)들을 집어넣어야 하기 때문에 처음에 넣었던 의미가 퇴색될수도 있으며 병렬처리도 불가능합니다. 그리고 몇십개 또는 몇백개의 단어 집합으로 되어있는 문장들을 한 벡터에 다 밀어넣는다구요? 솔직히 상식적으로 불가능합니다.
이 #$$#같은 긴 문장을 죄다 한 #$%같은 벡터에 다 집어넣을수가 없어!
“You can’t cram the meaning of a whole %&!$# sentence into a single $&!#* vector!” – ACL201#
무슨말이냐구요? 한 벡터로 모든 문장을 표현하기에는 한계가 있어서 몇개가 의미가 잘 전달이 되지 않았네요. 그래서 가려진 오묘한 단어들이 있지요? F로 시작하는 단어가 잘 가려진것같습니다.
어텐션 (Attention)
그래서 Seq2Seq 에서 활용할수 있는 어텐션에서는, 인코더에서 Hidden State를 디코더에서 받기위해 단 하나의 컨텍스트 벡터(마지막 벡터)만을 전달하는것이 아니라, 계속적으로 중간중간 히든 스테이트를 디코더에게 몽땅 전달하게 됩니다.
왜냐구요? 뭔가 맥락을 가지고있는 벡터는 어쨌든 앞에서부터 차례대로 hidden state가 전해지기는 하지만, 이 단계가 지나갈수록 뭔가 정보를 잃어버리게 마련입니다. 물론 이러한 방법때문에 RNN에서 LSTM이나 GRU등이 등장하게 되었지만 그래도 마지막 벡터에 모든걸 밀어넣을수는 없는 노릇입니다.
따라서 모든 히든 스테이트가 전달되기는 하는데, 다만 모든걸 전달하기에는 행렬의 크기가 굉장히 커지니 softmax를 통해서 가중합을 구해서 그 상태에서 전달합니다. Seq2Seq에서 전달한 것보다는 조금더 모든 문장에 걸쳐서 벡터가 만들어진 결과라고 할수 있겠습니다.
그렇다면 디코더는 이와같은 많은 정보를 어떻게 처리하게 되는지 궁금할수밖에 없습니다. 전달받은 여러 Hidden State에 대해서 중점적으로 집중(Attention)을 해서 봐야할 벡터를 소프트맥스로 점수를 매긴후에 각각을 히든 스테이트에 곱해줍니다. 그리고 이 히든 스테이트를 전부 더해주어 하나로 합칩니다. 그렇게 되면, 소프트맥스가 큰 값이 대부분의 값을 차지하게 될것이며, 비록 많은 스테이트가 벡터로 전해졌지만 필요한 정보에만 집중한 그러한 맥락 벡터(Context Vector)가 만들어집니다.
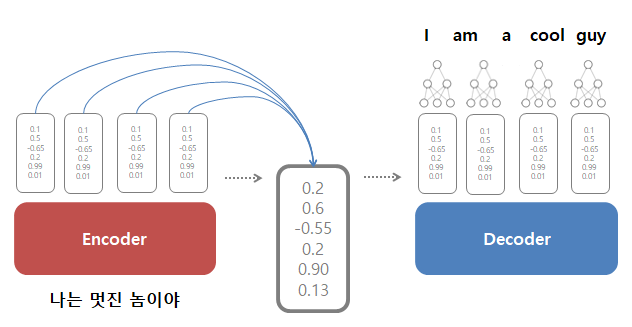
<END>토큰과 디코더의 초기 히든 스테이트를 받아서 새로운 히든 스테이트를 만들어내고, 위와같은 과정으로 맥락벡터(Context Vector)를 만들어내면 디코더의 히든스테이트와 해당하는 맥락벡터들을 적당히 이어붙여서 보통의 feedforward 신경망에 넣고 출력을 냅니다. 이 출력은 예를들어 나는 멋진 놈이야 -> I am cool guy 로 하나하나 결과를 내게 될것입니다.
트랜스포머 (Transformer)
트랜스포머에서는 Attnetion is All You Need에서 제안된 방법입니다. 서로다른 인코더와 디코더가 6개씩 포진하고 있으며, 하나의 인코더안에 self-attention과 feed forward 신경망이 포진하고 있습니다. 디코더안에도 마찬가지지만, 인코더-디코더 어텐션이 하나 자리잡고 있으며 이는 Seq2Seq모델에서 이용했던 방식의 어텐션과 동일한 방식입니다.
인코더에서는 각각이 512 사이즈의 벡터로 단어를 임베딩하며, 이를 셀프어텐션과 피드포워드 신경망으로 전달합니다. 셀프어텐션이란, RNN에서는 순서대로 처리했었지만 여기서는 해당하는 단어와 관련된 뜻을 찾기 위한 어텐션을 뜻합니다.
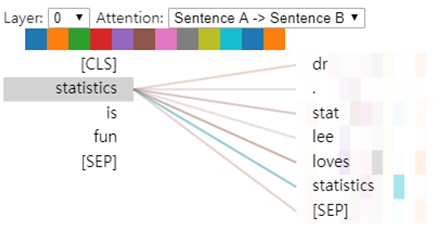
아래의 표를 보면, Dr. Stat Lee loves Statistics와 Statistics is fun 문장에대해서 서로 연관있는 단어끼리 연결이 잘 되어있는것을 볼수 있습니다. colab에서 확인하실수있습니다.
이를 구하기 위해서는 Query, Key, Value 세개의 벡터가 필요합니다. 이 세개의 벡터를 곱하여 셀프어텐션에 관련된 계산 값들을 구할수 있습니다. 예를들어 ‘사랑’이라는 단어와 ‘통계’라는 단어가 있으면 사랑이라는 단어에도 Q,K,V가 존재할것이며, 컴퓨터에 대한 단어에도 Q,K,V가 있습니다.
여기서 사랑이라는 단어에 주목할때는 Q(사랑) X K(사랑) 이라는 공식으로 점수가 나오게 되며, 사랑이라는 단어가 통계랑도 관련이 있는지 살펴보기 위해 Q(사랑) X K(통계)라는 공식으로 점수를 매기게 됩니다. 당연히 Q(사랑) X K(사랑)으로 산출되는 값이 더 크겠죠. 그래서 이렇게 산출된 값을 소프트맥스 변환시킨 다음에, 각각의 변환값을 V와 곱해서 이를 더하면, 다른 것들과 연관되긴 연관되었으나, 실제 영향이 많고 관련이 많은 것들이 점수를 많이 얻게 됩니다.
그렇다면 Q, K, V 가 무엇인가요? 셋다 훈련과정에서 나온 토큰들의 선형변환으로 튀어나오는 벡터지만 Query는 우리가 찾아야할 의미를 가지고 있는 토큰, 즉 위에서는 사랑이 되겠고, Key는 거기에 얼마나 연관되어있나를 찾아야할 토큰, 즉 사랑이나 통계가 되겠고, Values는 실질적인 컨텐츠가 되겠습니다.
다만 이렇게 한다면, 단어자체는 자신의 단어만에 집중을 하고있는 벡터가 대부분이 나타날것이니 다른 단어와 어떻게 연관되어있는지 잘 훈련이 안될수도 있습니다. 따라서 여러개의 어텐션, 즉 Multi-head Attention을 이용하여 이를 하나로 이어붙입니다. 그리고 이를 훈련시 얻어내었던 가중치 행렬을 곱해서 최종적인 벡터를 얻어냅니다.
즉 정리하자면, 다른 양상을 가진 데이터를 반영하기 위해 여러개의 셀프 어텐션을 통해 벡터를 산출하고 이를 하나로 통합하는 과정입니다.
트랜스포머에서는 몇가지 개념이 더 있는데, 하나는 Positional Encoding을 진행하여 단어별 위치를 인코딩함으로써 좀더 명확한 컨텍스트를 가지게 도와줍니다. 또한 적당한 노말라이제이션을 통해 셀프 어텐션 레이어에서 피드포워드로 전달될때 값을 훈련에 맞게끔 바꿔줍니다.

ELMo (Embeddings from Language Model)
BERT의 현재 모습에 영향을 준 모델입니다.
그저 단순하게 word2vec처럼 숫자로 변환시키는것보다 컨텍스트를 더 잘 이해하는 숫자로 바꾸는 방법이 필요한데, ELMo는 여기서 큰 역할을 했습니다. LSTM을 앞뒤로 움직여대면서 히든 레이어를 붙여서 가중치를 둔다음 컨텍스트를 포함하는 벡터를 만들어내었습니다.
ULM-FiT (Universal Language Model Fine-tuning for Text Classification)
텍스트 분석에서도 파인튜닝이 가능하도록 하였습니다.
BERT (Bidirectional Encoder Representations from Transformers)
BERT는 트랜스포머 인코더를 잘 쌓아놓은 훈련된 모델입니다.
BERT는 Transformer의 인코더만을 이용하며, 위치에 대한 정보도 Position Embeddings를 이용합니다. 임베딩은 보통 각 토큰에 대한 숫자변환이라는 결과를 가지게 되는데, BERT에서의 임베딩은 토큰에 대한 변환 + 그리고 문장 각각에 대한 위치 임베딩 + 단어의 문장에 대한 위치 임베딩 세개가 혼합되어 들어갑니다. Transformer는 인코딩을 하지만, BERT는 임베딩에 포함합니다.
토큰벡터는 768차원이라고 했을때, 이를 12등분하면 64개씩의 토큰을 가지고 각각 부위별로 12번 어텐션을 돌린 결과가 되고 이를 하나로 합치면 텍스트의 여러 면을 잘 적용한 벡터가 나타나게 됩니다. 또한 위에서 가중합등을 구할때 쓰인 QKV각각이 서로 다른 토큰에 의해 어텐션을 받기 때문에 각기 다른 부분을 잘 포함하는 모델이 나옵니다.
BERT는 몇몇 단어들을 마스크로 가려놓고 이를 맞추기위한 모델링을 합니다. 또한 몇개의 단어들은 일부러 포지션을 바꾸기도 함으로써 여러 면을 상징하는 어텐션을 통해 예측하고자 합니다. 또한 현재의 문장과 다음문장간의 관계를 예측함으로써 예측력을 또 올리고자 합니다.
이중 마스킹되는 비율은 15%정도이며, 이중 또한 10%는 일부 랜덤하게 바뀌고, 10%는 원래의 단어로 치환합니다.
BERT는 또한, 위키피디아를 이용한 여러 데이터를 이용해 pre-trained된 모델이 벌써 존재하는데요, 나중에 fine-tuning과정을 거쳐 제대로 교사학습을 시도하면 됩니다. 여러가지 방법이 존재하는데, 아래와 같은 그림으로 요약될수 있습니다.

실제 벤치마킹용 BERT-BASE, 인코더가 12개가 있으며, BERT-LARGE의 경우 인코더가 24개가 있습니다. 대부분의 State-Of-The-Art 성능을 내는 모델은 BERT-LARGE지만 개인적으로 GPU를 가지고 돌렸을때는 배치사이즈를 한없이 작게 가져가야 하는 슬픈 일이 생깁니다. 둘은 각각 768개, 1024개의 피드포워드 신경망이 있으며 run_classifier.py를 가동시킬때 역시나 파라미터로 설정할 때 자주 볼수 있는 숫자입니다.
실제 BERT Fine-tuning colab 이 있는데, TPU를 설정해놓고 쓰다보면 구글에서 처음 가입하면 주는 300$의 소중한 크레딧이 순식간에 날라가기 때문에 조심하셔야 합니다.
XLNET
XLNET은 Transformer XL을 이용합니다. Transformer XL은 트랜스포머의 셀링 포인트였던 시퀀스를 한꺼번에 넣고 처리하던 부분 (RNN계열은 하나씩 연속적으로 처리가 되지만) 에다가 RNN과 같은 개념을 다시 적용합니다. 즉, 단어레벨이 아니라 문장레벨 (시퀀스레벨)로 Recurrency를 심었다는 것입니다. Position Embedding은 어떻게 할지 이슈가 발생할수는 있지만 단어사이의 상대적인 관계에 의해 계산이 됩니다.
BERT의 기존 방법은 [MASK]를 뚫어 놓고 이를 맞추는 식으로 훈련했는데, 한 시퀀스 안에서는 동시다발적으로 이를 맞추기 때문에 서로 연관성이 있는것도 연관성이 없게끔 훈련이 될수 있는데, 이러한경우에는 시퀀스마다 RNN처럼 연관성을 가지는것이 더 나을수도 있습니다.