이미지 분류 문제에는 다양한것들이 존재한다. 사진에서 어떠한 물체가 있음을 탐지함에 있어서는 Object Detection, 사진안에 명확한 물체를 마스킹하고 싶다면 Instance Segmentation정도로 부르는것으로 학계에서 통일이 된것으로 보인다.
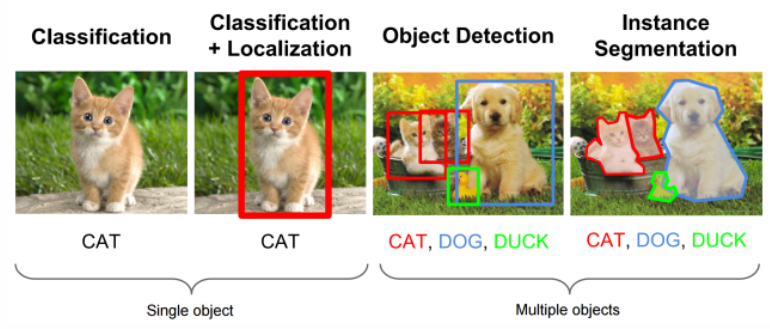
- 첫번째 작업은 분류 작업으로, 이미지가 물체를 포함하고 있다는것을 가정한 상태에서 그냥 분류만 하면 된다.
- 두번째는 지역화(Localization)이 포함된 개념으로 물체에 바운딩 박스를 그려준다.
- 물체 탐지 (Object Detection)은 사진에서 다량의 물체를 바운딩 박스를 쳐가고 이의 물체에 대해 분간하는 작업으로 통칭 불린다. 이정도면 자율주행까지도 가능하다.
- 객체 분류 (Instance Segmentation)은 통칭 픽셀마다 물체를 탐지하여 이를 마스킹 해주는 작업까지 포함되어있다.
넷은 사실 별개의 작업이 아니다. 사실은, 오른쪽으로 갈수록 더 머리쓸게 많을 수밖에 없다.
이 글에서는 맨 오른쪽의 Instance Segmentation에 집중을 해 이에 대한 몇가지 개념과 발전사항을 정리해 보도록 한다.
옛날 옛적..
약 20년전에는 한땀한땀 만든 SIFT, HOG등을 이용해서 원하는 물체의 방향성이나 엣지를 알아차리고 이들을 통해 feature를 골라낸 뒤 SVM을 통해서 최종적으로 분류하는 과정을 거치기도 했다. 하지만 CNN이 등장한 이후로는 모든것들을 딥러닝으로 퉁치려 하는 시대적 흐름이 태어났으니..
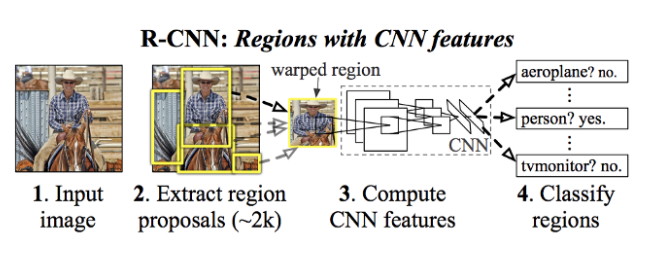
R-CNN (Regional Convolution Neural Network)
- R-CNN은 물체가 있을만한 공간을 Region이라 하고 이 Region을 각각의 CNN을 태워 feature를 뽑고 최종적으로 SVM을 통해 물체가 무엇인지 구별한다.
- 일단 사진이 주어진 상태에서, 물체가 있을만한 공간을 뒤져야 한다. 이 후보 공간들을 제시해주는 과정이 Region Proposal 이라고 말해보자.
Selective Search Algorithm
- 이 후보 Region들을 산출해내기 위해서는 Selective Search Algorithm을 쓰게 된다. 2013년의 알고리즘이며, 최대한 많은 후보군을 뽑기위해 그림들을 최대로 분할한다.

위와같이 굉장히 많이 region이 도출되지만, 너무 쓰잘데기 없는 region이 많이 나오기때문에, 이 region들이 이웃들과 크게 다른게 없으면 약 2000개가 나올때까지 줄인다.
유사도는 shape, texture, color, size 네개의 항목으로 계산한다.
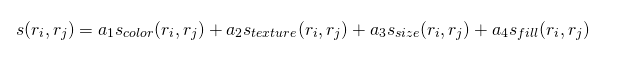
이걸 계속 계산해나가다 보면, 유사도가 상당히 높은 애들은 서로 하나가 되면서 그냥 저냥 유니크한 모습을 한 큰 region이 도출이 된다. 이를 필요한 수준까지 합치되, R-CNN에서는 약 2천개 가량을 놔둔다.
CNN with SVM
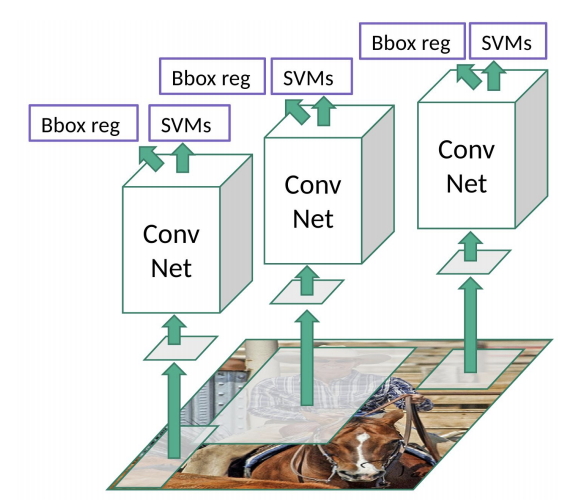
결과물은 상자를 표시할 Regressor와, SVM을 통해 Region안에 있는 물체가 도대체 무슨 물체인지 확인을 하게 된다.
이제, 각각 영역별로 모양이 다르고 형태가 다를수 있으니, 하나하나 가지고 와서 CNN을 태운다. 사진 하나당 약 1분이 걸리니, 실시간에서는 써먹지 못하는 단점이 있다. 무엇보다 이것이 제일 큰 단점이다.
Fast R-CNN
저자(Girshick, 2016)는 Fast만 달아서 좀더 빠른 R-CNN을 만들어내었다.
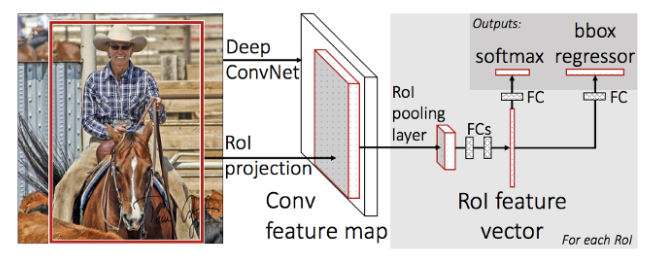
R-CNN은 총 세단계로 이루어져있는데, 첫번째는 Region후보를 찾는것, 각각 CNN을 태우는것, 그리고 마지막으로 SVM으로 분류하는 방법인데, Fast R-CNN은 이 세가지를 하나의 통으로 묶어놓았다.
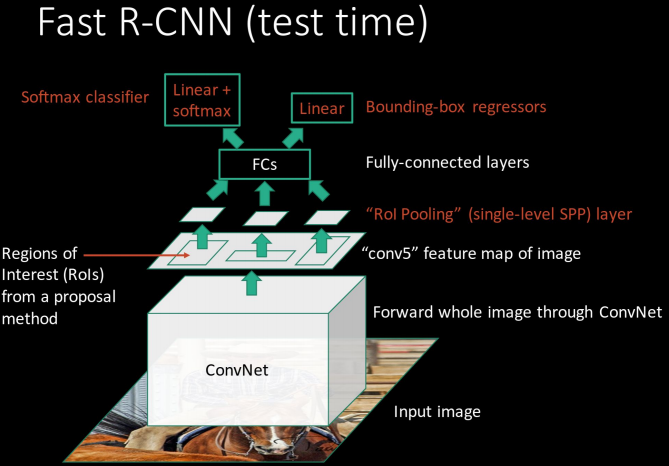
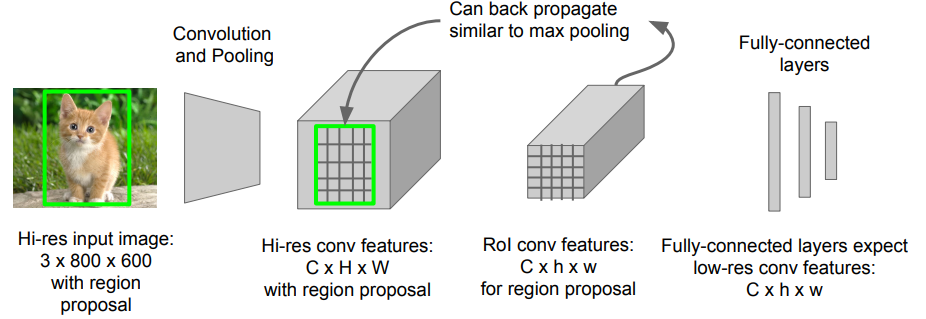
Selective Search를 통해 Region후보들을 뽑는건 그대로이기는 한데, 수도없이 많은 2000개의 각각의 CNN을 태우기보다는, Region들이 적당히 FC에 도달할수있도록 변형할수 있게만(RoI Pooling) 하고, CNN은 한번만 계산이 되어야 계산이 적다.
따라서 전체 이미지를 한번 변환해서 Feature Map을 만들어 내고 이를 다시한번 RoI Pooling과정을 통해 Region들을 고정된 형태로 만들어 준다.
그리고 적당히 변환된 Region을 가지고, FC(Full Connected) 신경망을 태워서 나오는 값으로 하나는 Softmax를 통해 각각의 확률값이 나오게 하여 제일 확률값이 높은 물체로 예측하고, bbox regressor에서는 정확한 바운딩 박스의 예측을 하게 된다.
왜 SVM을 쓰지않을까?
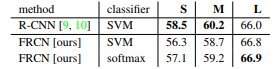
실험결과는 FC -> Softmax로 처리한 결과가 미세하게 나은편이며, Fast RCNN은 RCNN보다는 정확도가 높아지지는 않는것도 또한 확인가능하다. 또한, SVM은 훈련과정을 같이 따라가는것이 아니라 어디선가 훈련시켜놓은 모델을 (Post-Hoc)을 가져와서 판단을 해야한다. 하지만 Fast R-CNN구조에서는 한번에 통 구조를 훈련할수 있게 된다.
속도는 약 10~20배정도가 개선되었다. 이미지당 5초안에 판단하게 되었다.
Faster R-CNN
직접 이미지에 가져다대고 Selective Search도 예전의 무작정 찾는 알고리즘보다는 훨씬 합리적인 방법이였으나, 아무래도 몇개가 될지 모르는 후보 Region Segments들을 다 뒤지면서 하나하나 합쳐가는 형태가 굉장히 시간소모가 많이 됨을 알수있다. 따라서 이 과정또한 신경망모델로 바꾼 방법이 Faster R-CNN이다.
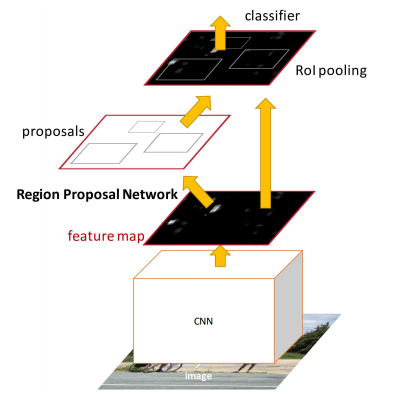
1저자는 중국에서 학교를 다니다.. 마이크로스프트의 인턴으로 있던 Shaoqing Ren..
RPN의 경우 feature map을 왔다갔다 거리면서 물체인지 아닌지를 판단하며, box location regression은 슬라이딩 윈도우에 해당하는 위치 정보를 잘 전달해준다. 만약 Intersection-over-union이 0.7이상이면, 물체가 있다고 판단하여 region으로 생각한다. 다만 사이즈가 각각 다르기 때문에, 여러 사이즈의 sliding window를 준비해 놓을 수 있다.
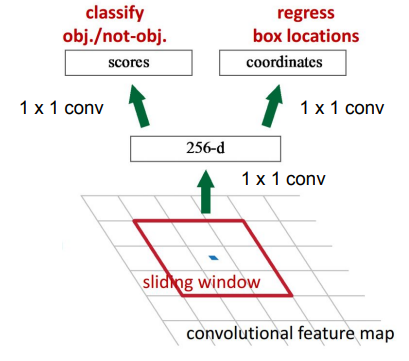
그리고 Faster-RCNN으로, 기존의 RCNN보다는 100배 이상빠르고, Fast R-CNN보다는 10배 이상 빠른 속도를 내게 되었다.
참조자료