데이터분석 방법을 크게 두가지로 나눠보자.
- 음성, 이미지, 텍스트처럼 딱 떨어지는 데이터가 아니여서 중요한 feature를 추출하는 작업이 필요할때.
- 기업 DB의 테이블처럼 tabular형태로 저장되어있는 정형화된 데이터 형태.하나하나의 컬럼이 정확한 의미를 지니고 있음.
첫번째의 경우는 딥러닝이다. 이미지 인식과 같은 경우는 훈련을 시키려면 feature가 있어야 하는데, 예전같으면 HOG, SIFT와 같이 그림의 움직임이나 특성에 대해 뭔가를 뽑아내는 작업을 통했다면, 지금은 그냥 컨볼루션 신경망이 알아서 feature를 뽑아내기 때문에 힘든 작업이 필요없다.
두번째의 경우의 winning 알고리즘은 부스팅이다. 부스팅이 항상 winning하는 알고리즘은 절대 아니다. 다만 각각의 상황에 따라 데이터가 컬럼으로 저장되어있고 이를 기반으로 뭔가를 분류해야하는 (ex. 고객이탈, 퇴직예측) 의 경우에는 부스팅이 빠르고 정확하게 높은 예측률을 확보할수 있다.
그러한 맥락으로 부스팅중 제일 빠르고 높은 예측력을 자랑하는 lightGBM은 모든 데이터 분석 2019년에도 계속해서 Competition에서 1등공신으로 나타난다. 기업에서도 안쓸 이유가 없다. 따라서 이에 대한 핵심적인 이해는 확실히 필요하다고 본다.
부스팅 (Boosting)
부스팅은 여러개의 트리(혹은 다른 모델)를 만들되, 랜덤포레스트나 배깅과 같은 기법과는 다른게 기존에 있는 예측기를 조금씩 발전시켜서 이를 합한다는 개념이다. 랜덤포레스트는 병렬로 무지막지하게 많은 다양한 결정트리를 동시에 만든다면 부스팅은 점진적으로 디시전 트리를 발전시킨뒤에 이를 통합하는 과정을 거친다고 보면된다. 부스팅은 보통 두가지 방향이 있는데,
- adaboost와 같이 중요한 데이터에 대해 weight를 주는 방식 (중요한 데이터를 순간적으로 weight만큼 뻥튀기시킨다고 보면 됨) 이 하나
- GBDT와 같이 딥러닝의 loss function 마냥 정답지와 오답지간의 차이를 훈련에 다시 투입하여 gradient를 적극 이용해서 모델을 개선하는 방식. XGboost나 lightGBM이 여기에 속한다.
가 있다. 아래는 gbdt 예로 xgboost 논문에서 발췌한 그림이다.

Gradient Boosting Decision Tree
GBDT는 딥러닝에서 쉽게볼수있는 개념인 gradient를 이용해서 트리를 만들어 낸다.
그라디언트는 무엇인가?
정답에 대한 경사(Gradient)를 뜻한다고 볼수있다. 즉 정답이 0인데 10을 맞췄다고 하자. 틀린 10을 보정하기 위해 여러가지 모델 파라미터를 조절하는 과정은 마치 loss를 줄이는 골짜기 방향의 경사진 곳으로 이동하는것과 같다. 차이를 한번에 좁혔다가는 그냥 저쪽 골짜기 반대편으로 이동하든지 에버레스트로 가버릴수있다. 이러경우 loss에 nan이 찍히는것을 하염없이 바라볼 것이다. 적당한 learning rate으로 조절한다.
트리란 무엇인가?
트리는 분기다. 일단 트리를 구성하려면 분기를 어디서 해야하는지가 관건이다. 최대한 쪼갰을때 각각의 쪼갠 데이터들이 이질적이여만(불순도가 감소하는 만큼 정보 이득이 있다) 잘 나눴다고 할수있다. 예를들어 손님의 성별을 구별할떄 머리길이라는 꽤나 좋은 힌트가 있다면 분기문을 적당히 잘 만들면 얼만큼은 서로 이질적으로 구별할수 있다. 만약, 날씨가 더운지에 여부를 이용하여 성별을 구별한다고 하면 아무 소용이 없다.
그럼 그냥 쓰면 되지 대체 문제가 무엇인가?
gbdt는 트리모델이 베이스기 때문에, 분기를 효율적으로 해야한다. 그런데 컴퓨터는 이걸 계산하는데 시간이 걸린다.
다뤄야할 데이터셋은 전체 데이터셋의 행 갯수이다. 한두개면 금방하겠지만, 종종 우리가 사용할수있는 데이터는 feature가 1000개가 넘을수도 있고 row수는 억이 넘어갈수도 있다. 게다가 내부적으로 각각 feature마다 정렬도 필요할수 있다. 그렇다고 한다면 효율적인 분기를 계산하는데 순식간에 어마어마한 계산량이 필요할수 있다. 따라서 feature를 줄이거나 row를 줄이면 속도개선에 많은 도움을 준다.
따라서, xgboost나 lightGBM은 큰 테이블 형태의 데이터가 있을때 세로를 줄이거나 (데이터 갯수) 가로를 줄이거나 (feature column)에 대한 문제를 효율적으로 다룬 라이브러리들이다.
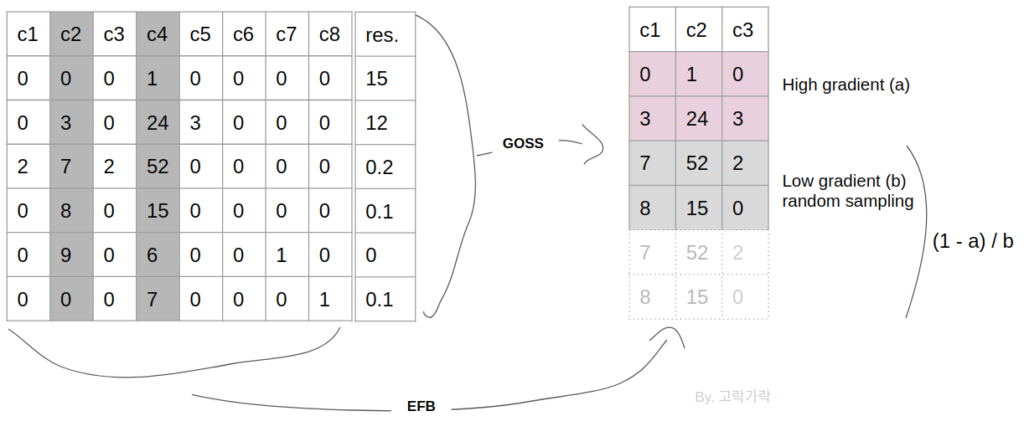
부스팅은 어떤식으로 경사를 계산해서 발전하나?
신경망은 back propagation을 통해 업데이트를 한다면, 부스팅은 약간 다를수있다. 일단 잔차를 이용한다. 만약, 원래 쓰던 x피처가 있다면, 여기에 전 단계에서 틀렸던 r값을 더 고려해서 x1 + x2 + x3 … + xn + r = y 로 모델을 적합한다. 무작정 피처로 넣기보다는 보통은 학습률을 계산한다. 이렇게 해서 계속적으로 잔차를 고려해서 모델을 만들게 된다.
LightGBM의 특별한 레시피
GOSS (Gradient based One Side Sampling)
GBDT에는 weight는 없지만, gradient가 있다. 따라서 데이터 갯수를 내부적으로 줄여서 계산할 때, 큰 gradient를 가진 데이터는 놔두고 작은 gradient는 랜덤하게 드랍한다. 작은 gradient만 drop하므로 one-side sampling 이라고 부른다. 여기서 gradient는 잔차를 이용하는것으로 이해하면 된다.
하지만 만약 gradient가 적다고 해서 버려버리면, 데이터 분포자체가 왜곡되기 때문에 이 상태에서 훈련하면 정확도가 낮아지게 되는데 따라서 낮은 gradient의 값들은 가져와서 버린 샘플만큼 뻥튀기한다. 1 – a / b 를 곱해서 수를 맞춰준다. (a는 탑n개의 비율, b는 샘플링n비율)
일단 제일 큰 gradient를 가지는 (절대값으로) 놈부터 랭크를 시킨다. 그리고 큰 gradient를 가지는 애들은 100%를 취하고, 작은 gradient 애들은 작은 비율만 선택한다. 논문에서 샘플링 비율인 a와 b를 찾는것은 추후의 과제로 남겨져 있으니, 이 숫자는 임의로 선택하기로 한다.
그리고 분기를 계산할때는 보통은 분산을 계산하게 되는데 아무래도 gradient가 적은 데이터는 샘플링이 되었으므로 적어진 비율만큼 다시 1 – a / b 를 반영해주어 분산을 계산한 후, 정보이득이 제일 큰 쪽으로 분기를 한다.
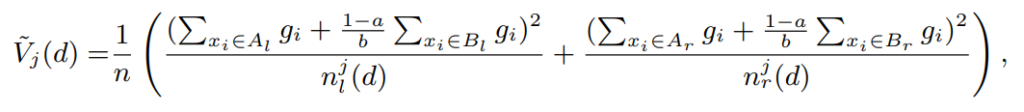
이제 이에대한 알고리즘을 대략적으로 다시 정리해본다.
- 모델로 일단 예측한다.
- 실제값과의 error로 loss를 계산한다.
- loss대로 정렬한후, 상위 N개를 뽑아 topSet에 저장. 전체데이터셋을 100으로 봤을때 30개를 뽑았다면 a는 0.3
- 나머지는 70개 중 10개만 랜덤샘플링 한다. (b는 0.1)
- 데이터는 전체데이터 대비 30%의 고 그라디언트 + 전체 데이터 대비 10%의 스몰그라디언트로 다시 샘플링 된다
- 마지막으로, 줄어든 스몰 그라디언트에 대해 weight를 (1-a/b) 적용
- 사용되는 줄어든 데이터를 대상으로 전체 데이터셋 + LOSS + WEIGHT 를 모두 고려한 데이터셋으로 약한 예측기를 만들어 전체 예측기셋에 추가한다.
논문에서는 이 방법이 데이터가 많았을때 정확도를 해치지 않음을 수학적으로 증명해내고 있으며, 실질적으로 보통의 competition에는 lightGBM은 확실히 xgboost와 비교해서 떨어지지 않는 정확도를 보인다. 좀더 나아가서 사실은 랜덤샘플링 하는방법이 배깅과 맞닿아 있어서 좀더 다양성을 높여 오히려 generalization이 잘되는 측면도 있을수있다. 그래서 실제 벤치마킹을 해보면 lgb가 미세하게나마 정확도에서 1등을 기록하는 경우도 많다.
EFB (Exclusive Feature Bundling)
실제 데이터에서는 원핫인코딩과 같이 0이 굉장히 많은 희소행렬 형태인 경우가 많다. 예를들어 한 컬럼에 100 종류의 데이터가 있고, 이를 원핫인코딩한다고 하면 feature가 100개 늘어나게 된다. 사실 트리모델에서 이렇게 상호 배타적인 (컬럼중 하나에만 값이 있고 나머지는 0인 경우) feature들은 하나로 통합이 가능하며, 이를통해 많은 계산량을 아낄 수 있다.
그리고, 만약 feature까리 완전 비슷한데 몇가지만 값이 같다면 (수치형으로는 correlation이 높은) 몇가지 값들의 충돌을 무시하고 합쳐버리면 계산량을 좀더 줄일수 있다. 일종의 차원축소 기법이라고도 생각하면 된다.
이는 알고리즘중 유명한 graph coloring 알고리즘과 동일하며, 상호배타적인 feature가 아닐때는 간선을 더하는 알고리즘으로 작동을 한다. 다만, 빠른시간안에 구하고자 greedy방법을 쓰므로 근사 알고리즘이다.
결국에는 계산량이 data수(row) x feature수(column)에서 row X 합쳐진column(bundle) 이 되어 상당한 수의 계산이 줄어들수있다.
다만 EFB 과정을 하는데 두가지 이슈가 있다.
– 첫번째 : 어떤 feature가 골라내져야 하는지?
weighted 엣지가 있는 그래프를 만들고 이 weight는 feature간 충돌상태로 둔다. 그리고 이대로 정렬을 한다음에 내림차순으로 둔다. 그리고 feature들을 체크해가면서 기존 번들에 넣든지, 혹은 충돌이 많다면 새로운 번들을 만들든지 한다. 감내할 수준이 K개라고 하면, K개가 될때까지 카운트하다가 이 이하면 기존 번들에 추가하고 넘어가면 새로운 번들을 만든다.
– 두번째 : 번들의 구성요소는 어떻게 만드는지?
만약 한 feature의 분포가 0~20이고 한 feautre의 분포가 0~30이면 뒤쪽 feature 에다가 10을 더해서 10~40이되도록 만들고 이를 합칠 수 있다. 이렇게 되면 트리모델에서는 feature마다 서로 간섭이 없으며 기존의 충돌이 났던 부분에 있어서도 커버가 가능하다.
히스토그램 방식의 분기는 하지 않는가?
논문에서 이부분은 많이 축약해놓기는 했는데, 기본으로 동작한다고 한다. 다만 좀더 개선된 히스토그램인것이 0은 고려하지 않는 히스토그램을 만들어서 분기하기 때문에 좀더 나은 형태의 히스토그램을 이용한다고 한다. 또한 히스토그램을 이용하기 때문에 계산이 빠르다. 다만, 메모리와 계산량 측면에서 장단점이 있는것으로 보여 저자의 자신감이 살짝 떨어지는것처럼 읽힌다.
실제 성능 비교
실제 성능비교는 0.00001을 다투는 competition에서 항상 기본요소로 등장하는 lightGBM으로 벌써 검증된것이 사실이고, 이 방법을 쓰지않는 방법이 차라리 굉장히 신선해보이는 현상까지 이르렀다. 논문에서는 아래와 같이 계산속도와 정확도 두개를 비교한다.
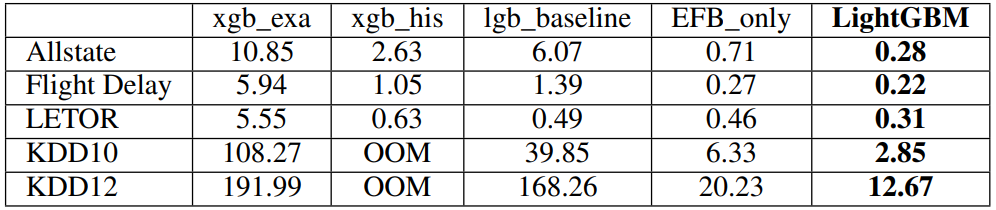

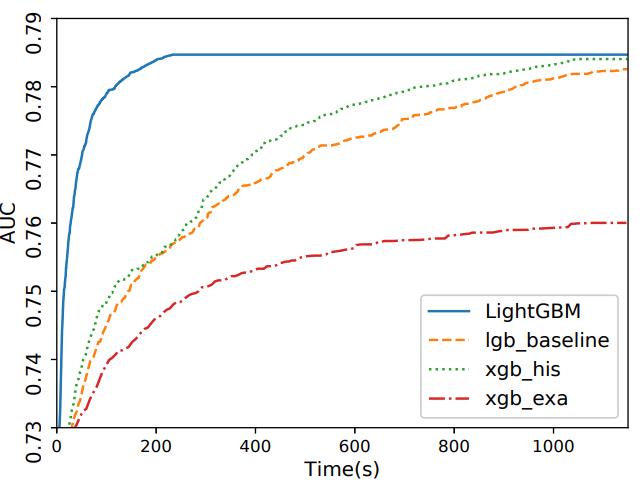
몇가지 실제 상황 팁
여기서 부터는 논문에는 없는 내용이다.
라벨인코딩이 좋은가?
lightgbm은 카테고리형태의 타입을 넣으면 알아서 분기하는데, 라벨인코딩이 약간의 정확도가 좀더 높은것으로 대회에서는 사람들이 인식하고 있다.
feature bundling 방법은 NPhard 문제이기 때문에 다항시간에 최적화된 답을 못 구하기때문에 근사알고리즘을 쓰는데, 라벨인코딩을 해도 되는 경우가 확실한 경우 라벨인코딩을 쓰는것이 나은것으로 생각된다.
많은 파라미터를 어떻게 최적화하나?
파라미터 최적화는 grid search, random search등이 가능하지만 실제 competition에는 이 파라미터 최적화를 손으로 하거나 (거의 많이 하지 않는다는 뜻이다.) 혹은 bayesian optimization을 이용해 최대한 빠른 속도로 하이퍼파라미터를 추정하는 방식이 인기가 많다.
파라미터 최적화 보다는, 시간이 허용된다면 조금이나마 Feature Engineering을 고민하는 하는편이 좀더 얻을수 있는 기대 효용이 크기 때문이다.
생각보다 컴페티션에서 파라미터 최적화만을 한다고 생각하는 부분이 많은데, 최상위권에서는 오히려 하나같이 대회 막바지에 이르러서 튜닝하는것으로 보인다.
파라미터에 설명은 어디갔나?
https://gorakgarak.tistory.com/1285 에 중요한 파라미터는 정리되어 있으나, 다음편에 조금더 정확히 적어보도록 한다.