lightGBM에는 무수히 많은 파라미터가 있다. 다만 기억할것은 정답이 없다는것이다. 생각보다 하이퍼파라미터 튜닝에 시간을 많이 쏟지는 않는 이유는, 어차피 ensemble형식이기 때문에 구조자체가 파라미터에 맞게 큰그림에서는 맞춰질것이라, 그다지 정확도면에서 차이가 없을수 있다.
lightGBM / XGBoost 파라미터 이름순으로 정렬했다. 파라미터가 너무 많아서 어떤 파라미터를 만져야 하는지 우선순위가 있어야 해서 아래처럼 표기했다.
언급되지 않는 파라미터는 아예 중요도가 떨어진다고 생각해 생략.
| ★ | 튜닝할 필요없이 default값으로 놔두는걸 추천 |
| ★★ | 정밀한 튜닝을 할때 다음으로 고려해야할 파라미터 |
| ★★★ | 예측력에 지대한 영향을 주기 때문에, 여러가지 값을 시도해야함 |
- 병렬처리 – num_threads / nthread (★)
- 병렬처리시 처리할 쓰레드 기본값은 현재 사용가능한 쓰레드. 기본값설정 추천.
- 쓰레드말고 진짜 코어수대로 설정하라는 소리가 있는데 요즘은 안그래도 무방하다. 다만 다른작업이 필요한것같으면 코어 하나는 비워줘도 좋은 선택이다.
- 훈련량 – learning_rate / eta (★★★)
- 0.05~0.1 정도로 맞추고 그 이상이면 다른 파라미터들을 튜닝할때 편. 미세한 정확도 조정을 원하면 더 작게 둬서 마른걸레를 빤다.
- 한번 다른 파라미터를 고정하면 바꿀필요가 없다. 또한 쓸데없이 긴 소수점으로 튜닝하는것도 별 쓰잘데기가 없다.
- 반복량 – num_iterations / nrounds (★★★)
- 계속 나무를 반복하며 부스팅을 하는데 몇번을 할것인가이다. lgb는 기본값이 100이라 너무 적은편이다. 1000이상정도는 해주도록 한다. 너무나도 많이하면 당연히 오버피팅이 된다.
- early_stopping이 있으면 최대한 많이 줘도 (10,000~)별 상관이 없다.
- 조기멈춤 – early_stopping_round / early_stopping_rounds(★★)
- validation셋에 더이상 발전이 없으면 그만두게 설정할때 이를 몇번동안 발전이 없으면 그만두게 할지 여부.
- validation셋이 없으면 무용지물이다. testset은 무조건 정확도가 올라갈것이기에.
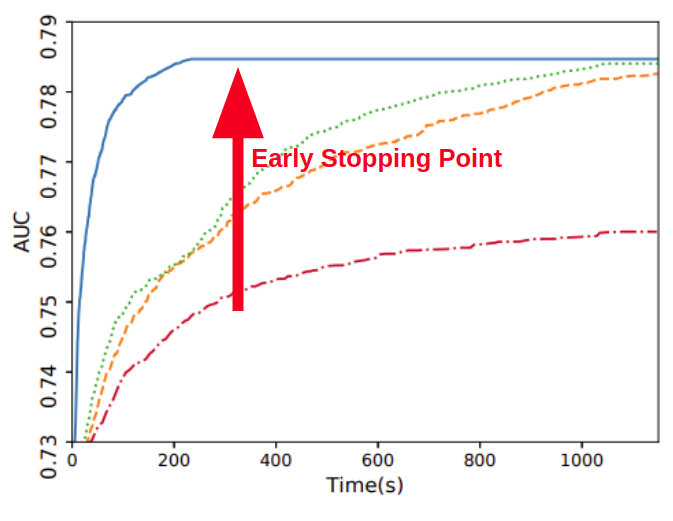
- 나무 깊이 – max_depth (★★★)
- -1로 설정하면 제한없이 분기한다. 많은 feature가 있는 경우 더더욱 높게 설정하며, 파라미터 설정시 제일 먼저 설정한다.
- default는 -1로 제한없이 분기한다.
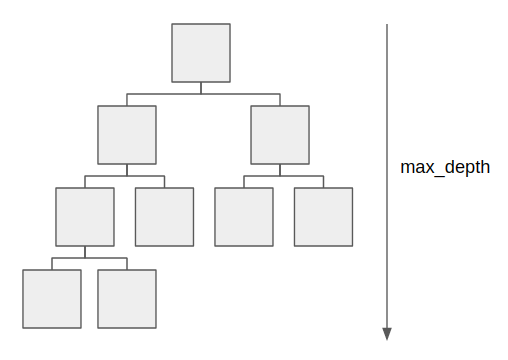
- 잎사귀 수 – num_leaves / max_leaves (★)
- 결정트리는 이진트리 형태이기 때문에, depth가 4라면 (2의 4제곱 – 1) = 15로 설정하면 그 트리가 가질수 있는 최대 잎사귀 수이다.
- 최대 잎사귀수보다 작으면 규제(Regularization)으로 작동한다.
- 행 샘플링 – bagging_fraction / subsample (★★)
- Row sampling, 즉 데이터를 일부 발췌해서 다양성을 높이는 방법으로 쓴다. 민감한 옵션이므로, Column sampling과 잘 섞어서 쓴다.
- lightGBM의 GOSS옵션을 쓴다고 하면 해당 옵션을 쓰면 에러가 난다. GOSS에서 알아서 샘플링하는 과정이 있기 때문

- 데이터 업데이트 주기 – baggin_freq / 부재 (★)
- iteration 몇번째에 해당하는 데이터를 업데이트 할것인지.
- XGBoost는 SGD를 구현하고 있기 때문에, 기본값인 1로 동작한다고 보면 된다. 영향도가 크지 않기 때문에 기본값 추천
- 열 샘플링 – feature_fraction / colsample_bytree (★★)
- 컬럼에 대한 샘플링을 통해 각각의 다양성을 높인다. 랜덤포레스트에 있는 기능이였으며, 보통은 정확도가 높아지는 면이 있다.
- 컬럼 샘플링을 하지 않는 1이 기본값이나, 0.7~0.9 정도로 세팅하는 편이 일반적임
- L1 규제 – lambda_l1 / alpha (★)
- L1 정규화를 하여 오버피팅을 막지만, 정확도에 어떻게 영향을 줄지 예측하기가 힘들어 default인 0으로 놔두는 편
- L2 규제 – lambda_l2 / lambda (★)
- L1 정규화와 마찬가지로 0으로 놔두는 편
- 히스토그램 빈 갯수 – max_bin (★)
- 히스토그램은 분기를 보통 빠르게 나누기 위해 쓰이는데, 결과적으로는 규제(regularization)로도 동작하게 되므로 모델의 예측력에도 영향을 준다.
- 적게 주면 빠르게 계산하고 많이 주면 느려지지만 조금더 이상적인 트리 분기를 찾는다. 기본값은 255로 그냥 놔두는 편.
- 히스토그램 카테고리 빈 갯수 – max_cat_threshold (★)
- 히스토그램을 만들때 카테고리컬 변수를 최대 몇개까지 unique하게 놔둘것인가에 대한 여부. 계산 속도가 급속도로 느려짐 기본값은 32. 정말 너무 많은 카테고리가 있는것이 아니면 줄인다.
- 충돌 비율 – max_conflict_rate (★)
- Feature Bundling실행시 충돌을 허용하는 비율을 얼마나 풀어줄지. default는 0이지만, 1미만까지 조정가능하다. 논문에서 강조한것과 다르게, lightGBM에서는 값 조정에 따른 큰 차이가 보이지 않는다.
- 샘플 스케일링 – scale_pos_weight (★★)
- 양성인 경우 이를 뻥튀기해준다. 불균형셋에서 유용할수 있으나 너무 많은 weight를 주는것은 오히려 정확도가 떨어진다. 기본값은 1이며 불균형이 얼마나 심한지에 따라 다르다. 1.1~1.5정도의 가벼운 조정은 경험상 괜춘.
- 나빠지든 좋아지든 정확도에는 상당한 영향을 미치므로, 적어도 불균형셋에 대해서는 시도해보고 변화량을 보는걸 추천
- 불균형 셋 조정 – is_unbalance (★)
- 마찬가지로 불균형 셋이라면 이 둘의 비율을 맞춰준다. 다만, 데이터 분포가 확연하게 달라지므로 정확도에서 떨어지는 경우가 많게 되므로 SMOTE등을 고려해보자.
- 평균에서 부스팅 – boost_from_average (★)
- 평균값에서 시작으로, 속도를 빠르게 한다.
- 피처 번들링 – enable_bundle / enable_feature_grouping (★)
- 피처 번들링에 대한 여부. 보통은 라벨인코딩을 직접해주고 피처 번들링 기능을 끄는것이 희한한 결과를 보지 않는 방법 중 하나다.
- 부스팅 방법 – boosting / booster (★★★)
- XGBoost에서는 gblinear / gbtree / dart 지원
- lightGBM에서는 rf (랜덤포레스트) / gbdt (Gradient Boosted Decision Trees) / dart (드랍아웃 Regression Trees) / goss (Gradient-based One-Side Sampling)을 쓴다.
- 기본적인 이론적 이해가 있은 뒤에 boosting을 고른다. 기본값은 gbdt로 대부분 쓰이며, 정확도가 중요할때는 딥러닝 드랍아웃과 같은 dart적용, 그리고 논문에서 강조한 샘플링을 이용한 goss 를 적용가능하다.
- GOSS는 계산속도를 상당히 줄여주지만 약간의 예측력 손상(혹은 규제로 작용)이 있을 수 있다.
- DART는 일반적인 경우 조금 더 나은 예측력을 보여주지만, 절대적인건 아니다.
- 트리 빌딩 방법 – tree_method (XGBOOST에만 있음) (★)
- 속도에 지대한 영향을 미치는 분기 포인트 잡을때의 히스토그램의 사용 여부이다. auto, exact, approx, hist가 있으며, hist가 제일 빠르나 exact가 일반적으로 예측력은 미세하게 높다.
- sketch_eps 라는 파라미터도 XGBOOST에만 있는데, 이는 빠르게 분기를 나누기 위해 e값을 조정하는데, 얘가 커질수록 빈은 줄어들어 속도는 빨라지지만 예측력은 내려간다.
- 드랍아웃 비율 – drop_rate / rate_drop (DART에만 해당) (★)
- 한 주기당 떨어뜨리는 나무의 비율. 이외에도 Max Drop / Tree Uniform Drop / Tree Normalization / Tree One Drop이 있다.
- XGBoost Dart 모드 – xgboost_dart_mode (★)
- GOSS에서 lr / (1 + 드랍된 트리갯수) 로 훈련량을 조절하게끔하며, 기본값은 false이다.
- 고 그라디언트 샘플링 – top_rate (★)
- lightGBM의 핵심인 GOSS에서 고 그라디언트를 가지는 데이터의 샘플링 비율. 즉 그래디언트순으로 정렬을 했을때 그중 100% 사용할 상위 %의 비율. 논문에서의 a다. 0.2가 기본값이다.
- 저 그라디언트 샘플링 – other_rate (★)
- lightGBM의 핵심인 GOSS에서 저 그라디언트를 가지는 데이터의 샘플링 비율. 전체 데이터 대비 비율이다. 기본은 0.1로 되어있으며, 논문에서의 b다.
- 기본값으로 더한 a+b는 0.2+0.1 = 0.3이며, 이는 전체 데이터의 30%를 뜻한다.
- 트리 학습기 – tree_learner / updater (★)
- GPU를 사용할것인가에 대한 여부. 기본값은 CPU이다. 생각보다 딥러닝과 다르게 GPU를 씀으로써 얻는 이득이 상대적으로 적다.
- 단순히 계산만 GPU를 해서 속도를 부스팅하는게 아니라, 몇가지 구성이 바뀌어 퍼포먼스가 좀 다르며 (CPU 우세) 속도가 가시적으로 빨라지기가 힘든데 세팅은 더 힘들다는 제보가 있다.
- 적은 깊이 (depth)를 가져야 GPU가 유리하다고 한다.
- Metric / Loss 관련 파라미터 (★★★)
- 당연히, 학습하려는 목적에 따라 다음의 metric을 설정하여야 하며, lightGBM에서 제공하는 파라미터는 다음과 같다.
- binary(Cross Entropy)
- multiclass(Cross Entropy)
- regression_l2(MSE)
- regression_l1 (MAE)
- mape (MAPE)
- poisson (Log Transformation)
- quantile (Quantile)
- huber (Huber loss, MAE approx)
- fair (Fair loss, MAE approx)
- gamma (Residual Deviance)
- lambdarank
- tweedie
적당한 파라미터를 찾는것은 중요하다. 다만 시간을 너무 쏟을 필요는 없다. 생각보다 크리티컬한 파라미터는 몇개 없기 때문에, depth / iteration / sample 등의 별 세개의 중요도를 가진 파라미터를 먼저 고치고, 그 이후에 별 두개를 위주로 조금씩 튜닝을 시도하면 될듯으로 보이면서 마친다.
참조
- 아래의 사이트가 대부분의 파라미터를 커버하고 있음.
- 아래의 lightGBM 명세서가 존재
- lightGBM Documentation