BiFPN은 FPN에서 레이어마다 가중치를 주어 좀더 각각의 층에 대한 해상도 정보가 잘 녹아낼수 있도록 하는 장치이며, 2020년 1월 Object Detection SOTA인 EfficientDet에 등장하는 개념이다.
예를들어, 컨볼루션 네트워크는 각각의 단계마다 다른 특징을 추출하게 되는데 FPN은 여러 해상도를 가지는 특징들 전부를 예측에 이용함으로써 정확도를 높였다.
찬찬히 원래 존재하던 CNN의 개념부터 살펴보면, 대충 (a)부터 (d),(e) 까지 역사적으로 발전된 측면이 있고, 정확도도 개선되었다.
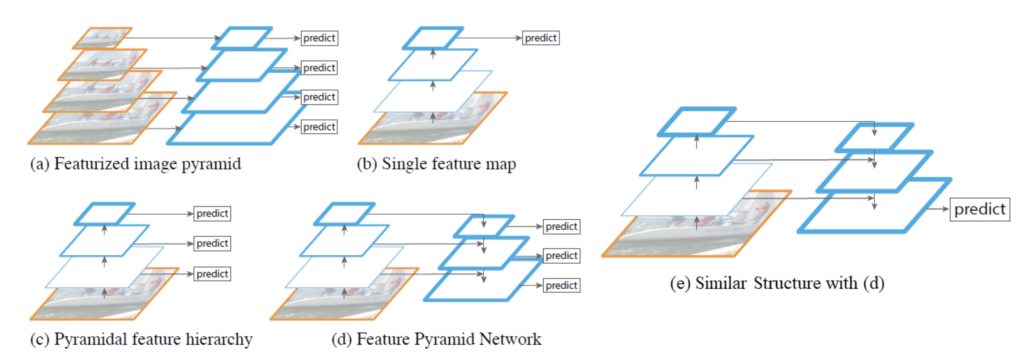
(a)는 딥러닝이 대두하기전, 다양한 해상도에서 특징을 뽑아내려고 노력하던 때, 즉 이미지를 줌인 줌아웃해서 특징을 골라내려 한다고 하고,
(b)는 초기의 CNN구조, 즉 계속 컨볼루션 필터를 적용하면서 최종 아웃풋을 내는 방법이다.
(c)는 각각의 단계에서 (a)와 같이 각각의 단계에 예측을 하지만, 그림에서 볼수있는 차이는 맨 아랫장의 그림에 predict가 없는것을 확인할 수 있다. 이것이 무엇을 뜻하는가? 밑장빼기인가? 컨볼루션 필터를 거쳤고, (a)는 이를 거치지 않았다는 차이점이 있다고 할수있다. 즉 뭔가 딥러닝이 들어갔는지 들어가지 않았는지에 대한 차이일수도 있다.
(d)는 FPN이다. 각각의 단계에 컨볼루션 필터가 적용되는데, 희한하게도 반대방향으로 흐르는 부분이 있다. 아이디어는 이렇다. 작은 해상도나 큰 해상도에서 얻을수 있는 특징을 적당히 섞으면 제대로 좀더 정교한 predict를 할수 있지 않을까? 하는 방법이다.
(e) FPN과 동일한데, 아웃풋이 하나인 U자형 구조이며, 대부분 의료 영상쪽에서 많이 쓰이는것으로 아직까지는 보인다. 왜냐면, 의료이미지에서는 오히려 피곤할정도로 많은 prediction은 목적달성에 별로 도움이 되지 않는것으로 보인다.
이제 FPN과 BiFPN의 차이점을 살펴본다.
FPN은 다른 이미지로 표현하면 아래와 같다.
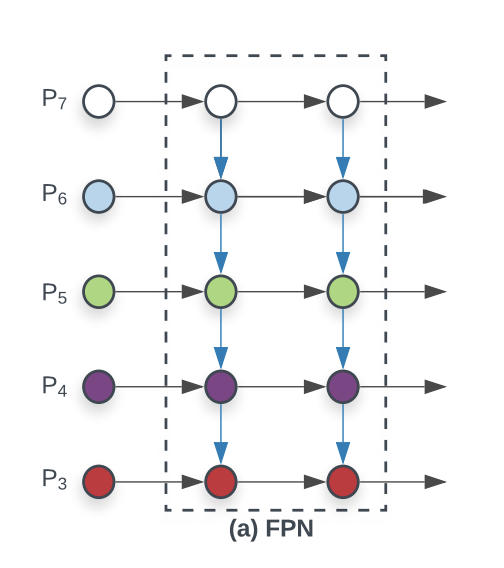
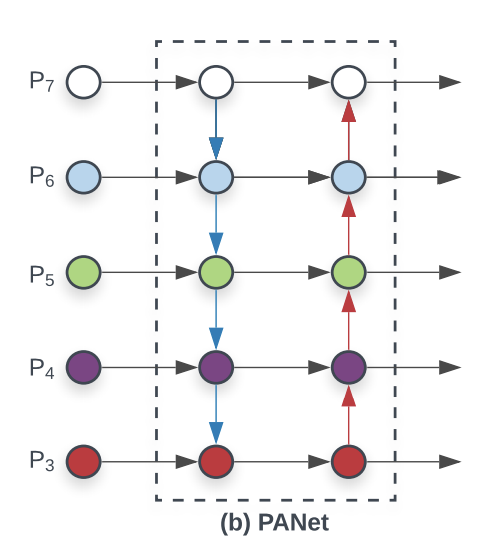
P3~P7은 모두 각각의 레벨에 따라 각각의 특징을 다음 레벨에 잘 녹여내는것을 표현한 그림이라면, FPN에서 한단계만 더 발전하여 다시한번 거꾸로 뒤집은 PANet을 참조해본다.
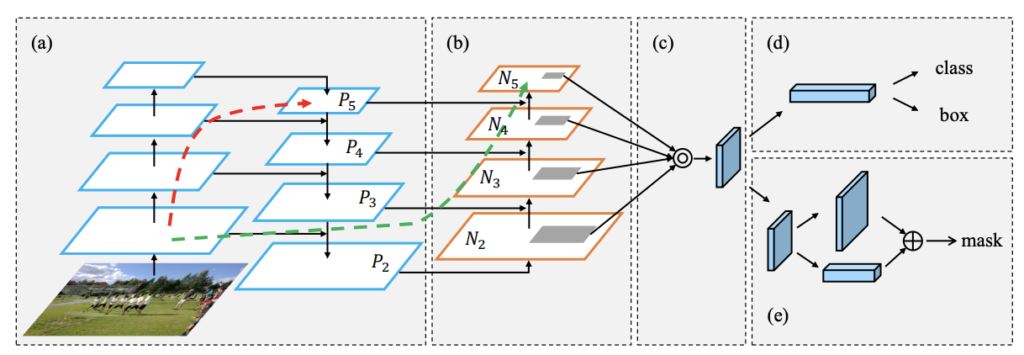
간단한 백본인 FPN의 탑다운에다가 다시 보톰업을 한개를 더 추가하여 좀더 괜찮은 정확도를 확보할 수 있었다고 말하고 있다. 이와같은 레이어 구조를 그림을 그린다면 아래와 같다.
이때 쯤이면, 사람들이 흔히 생각할 수 있는 문제는, 아니 저렇게 레이어끼리도 섞고 난리를 피는데, 그렇다면 이것저것 다 연결해서 이 자체를 신경망처럼 만들면 어떨까? 라는 생각이 들기 마련일것이다. 그래서 결국 태어나는 괴물이 아래와 같은 구조로 실험을 해봤으나..
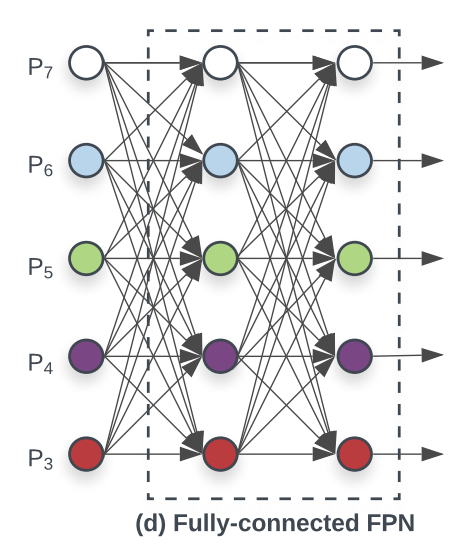
그렇지만 위와같은 방법은 나이스 트라이였지만 실험결과로는 그다지 정확도에서 향상을 보지 못한듯하다. 그리고 계산하는데 문제가 있을 수 있다.
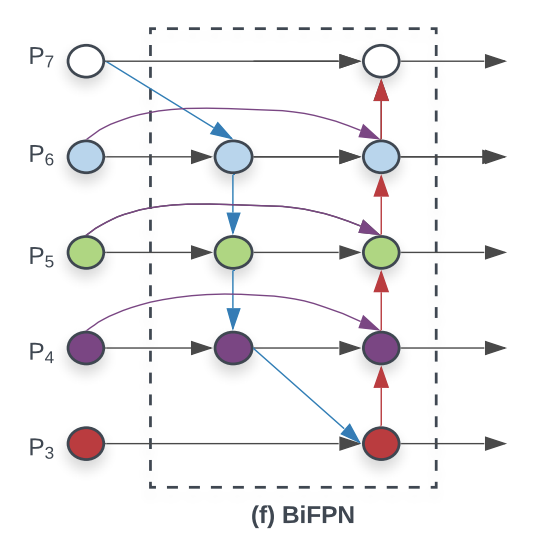
최종적으로, BiFPN은 위와같은 구조이다. PANet에서 처럼 보톰업과 탑다운을 동시에 지니고 있으면서도 여기저기 제일 중요한 인사이트를 줄수있는 곳에다가 길을 뚫어놓는다고 봐야할까, 이를 이용한 최종적인 구조는 아래와 같다.
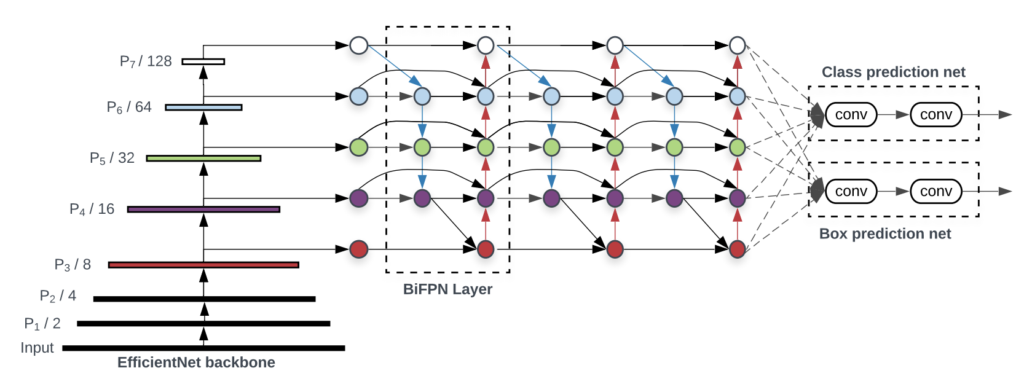
EfficientNet을 백본으로 하고, 오브젝트 디텍션까지 기능이 있는 EfficientDet이다. 백본을 몸통, Box Prediction Net을 머리라고 본다면, BiFPN Layer는 목 부분이라고 할수 있겠다.