코사인 형태로 훈련비율(learning rate)을 차츰 조정하면서 좀더 정확도를 상승시킬수 있는 방법이다.
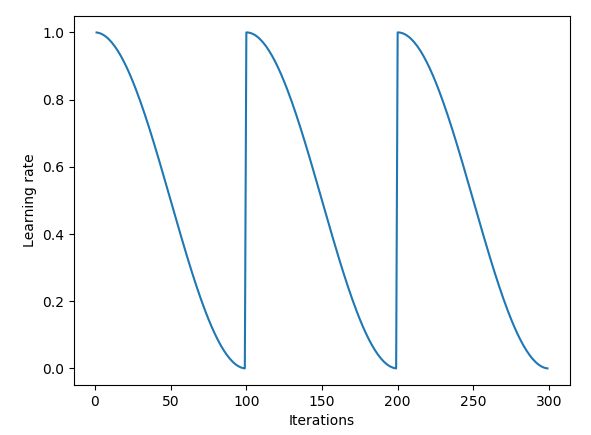
훈련시, 오차와 정답의 차이를 100% 바로 반영해서 가중치를 수정하는게 아니라, learning rate으로 지정되어 있는 정도로 훈련이 진행된다. 이 숫자는 보통 0.01 부터 대충 0.000001 정도 까지의 다양한 수를 골라 이 값으로 훈련할 수도 있지만다. 하지만, 이를 계속 변경하면서 여러 최적점을 탐색하거나 fine tuning과 같이 좀더 나은 최적점을 향해 찾아가게 할수있다.
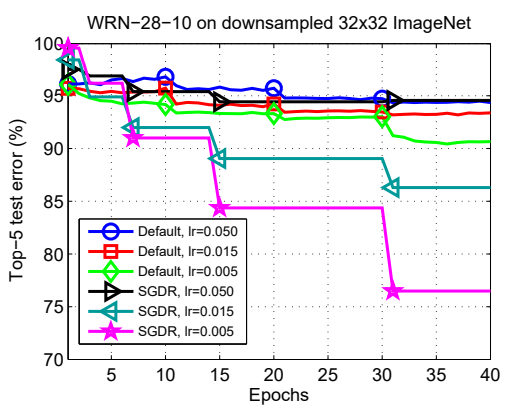
하나 더 추가적으로 보면 각각의 restart지점마다, 다른 모델이 튀어나올수도 있는데 이를 활용해서 앙상블로 정확도를 더 높일 수 있다.
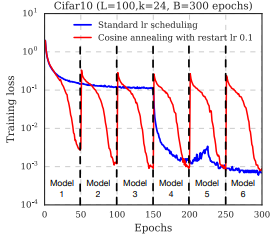
코사인 어닐링과 모델 체크포인트 앙상블 방법 실제로 모두 자주 볼수 있는 방법이지만, 코사인 어닐링은 1사이클만 훈련양을 낮춰가면서 해볼 수 있는 반면, 앙상블 방법은 여러 에폭을 돌려야 하기 때문에 시간이 오래걸려 feasibility만 보는 개발 단계에서는 시간제약이 있을 수 있다.
관련 논문 : SGDR: Stochastic Gradient Descent with Warm Restarts, Ilya Loshchilov, Frank Hutter / Snaptho ensembles : Tran1, Get M For Free