모델 시각화
이제 회귀분석을 이용하여, 신종 코로나 수를 확진하는 모델을 만들어 볼것이다. 다른 전염병과 정확히 얼마나 예상에 맞춰 움직이고 있는지에 따른 분석 모델을 만들 예정이다.
일단 초기단계부터 ~25일까지의 그래프는 다음과 같다. 확실히 신종 코로나 바이러스가 표가 기계로 그린것처럼 매끄럽기는 하다.
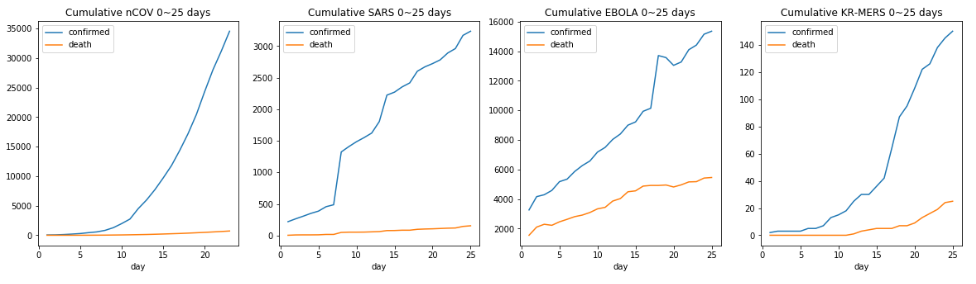
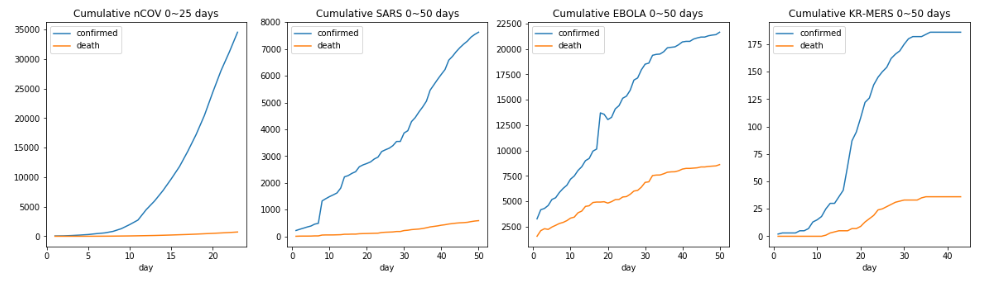
코로나 바이러스는 25일치가 전부이므로, 나머지 전염병과의 50일치를 비교 가능하다.
선형 회귀 (1차) 적합
이제 데이터가 준비되었으므로, 아래와 같이 모델 피팅을 시작한다. 코드는 아래쪽에 있으니 참고하면되고, 일단 1차 함수식을 만들어 본다.
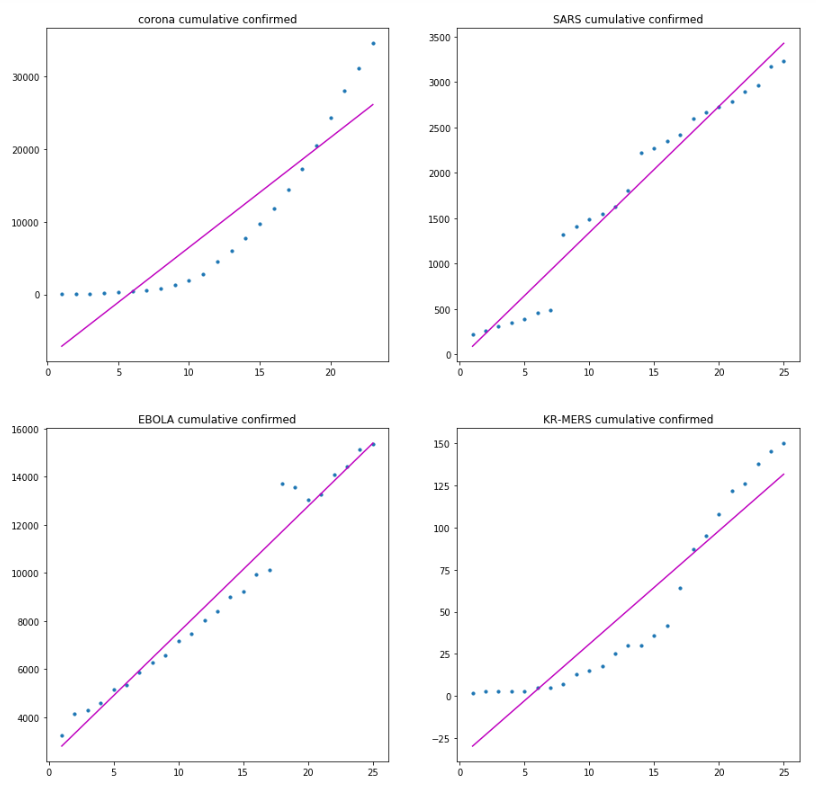
1차 적합의 경우는, 그다지 현상과 맞지 않으므로, 2차 적합을 해본다.
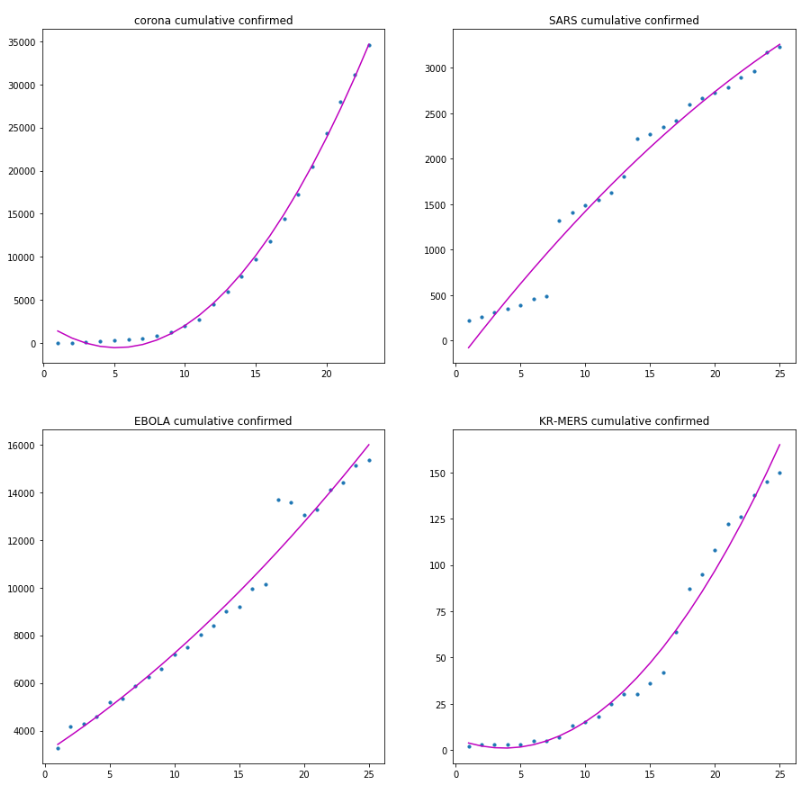
다항회귀 2차 함수 적합
2차 다항회귀의 경우는 먼저 x들을 1, 2차항을 만들어 계산하는 식으로 이용하면 된다.
확진자수 예측
사망자수 예측
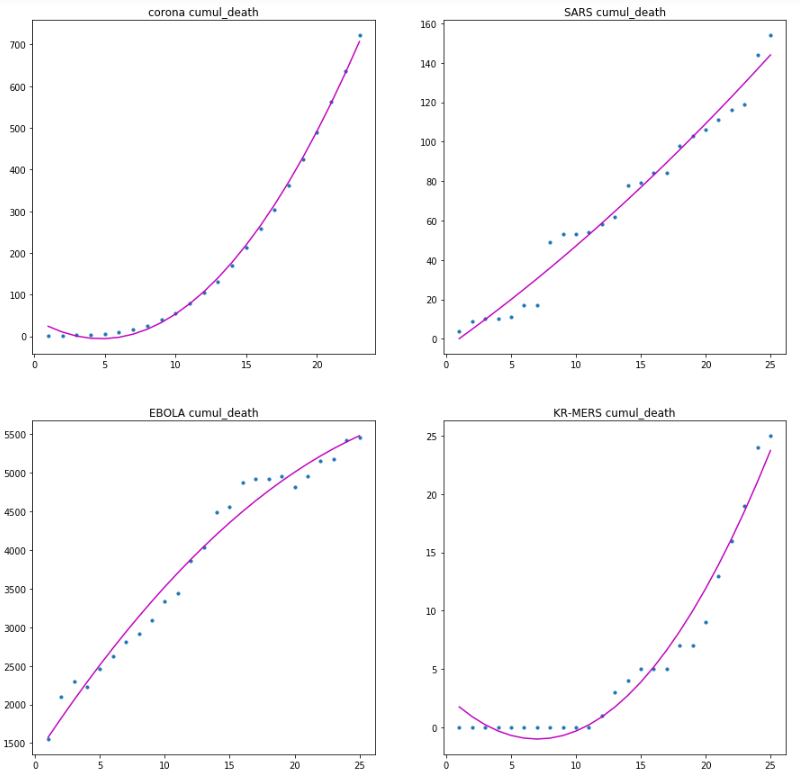
정확한 2차함수라고 하기에는 초반부가 조금 변동이 없는편에 속한다. 이게 굳이 조작된 그래프라고 해도, 별로 좋지않은 그래프이다. 기하급수적으로 증가하는 전형적인 초반부의 그래프이기 때문이다.
설명계수인 R스퀘어는 아래와 같다.
- 신종 코로나 : 0.9972
- SARS : 0.9727
- EBOLA : 0.9752
- KR-MERS : 0.9817
보통의 문과계 실험에서는 0.5 이상만 되어도 상관관계가 있다라고 말하며 완전 통제된 실험에서야 0.90 이상이 나온다고 혹자는 말한다. 그렇지만 이렇게 말하기는 약간 부족한게, 해당 그래프는 누적그래프이다. 따라서 시간에 따라 증가할수 밖에 없는 그래프이다. 설명계수를 산출하는 방식은
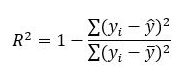
위와 같은데, 즉 두 모델을 비교하는것과 같다. 그냥 평균으로 예측하였을때의 결과와 예측이라는 과정을 통해 나온 결과를 비교하는 것이다. 시간에 따른 누적 그래프는 당연히 단조증가 그래프이므로 초딩이 그려도 무조건 R2는 유의하게 나올수밖에 없다. 전날에 비해 누적 확진자는 무조건 늘기 때문이다.
10차 함수 적합
차수를 올려서 N차 함수를 만든다는것 자체가 과학적으로 들릴수 있다. 하지만, 이는 정반대의 비과학적인 결과를 산출한다.
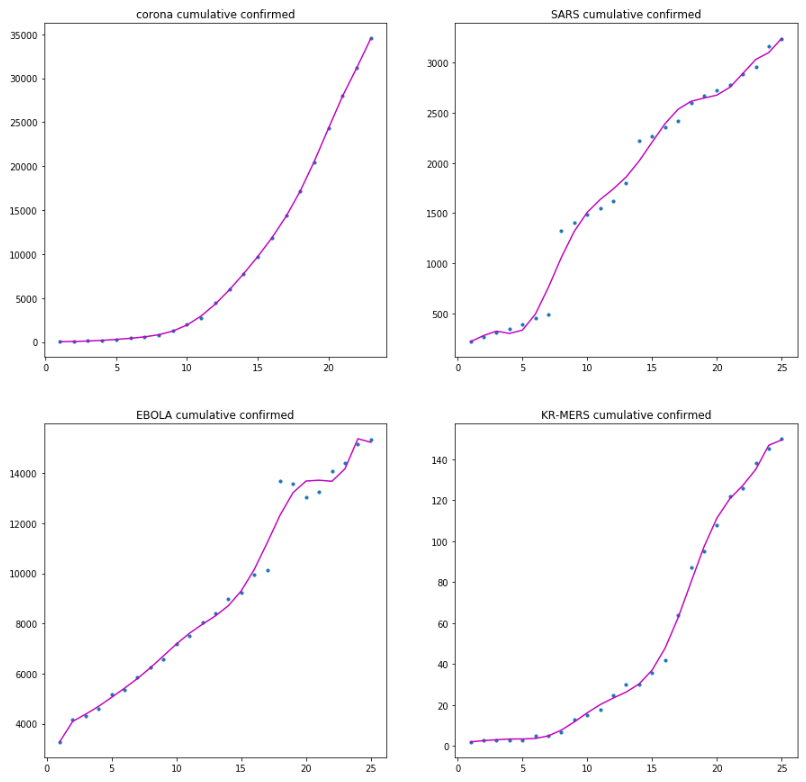
위와같은 그래프가 과연 잘된 회귀식을 나타내는 것일까? 모든 함수가 전부 설명계수가 0.99이상이다. 그렇지만, 이와같은 그래프는 과적합(overfitting)된 그래프이기 때문에 이러한 함수를 그려가지고 오면 신나게 두들겨 맞을 수 밖에 없다. 미래 구간에는 전혀 예측력이 없기 때문이다.
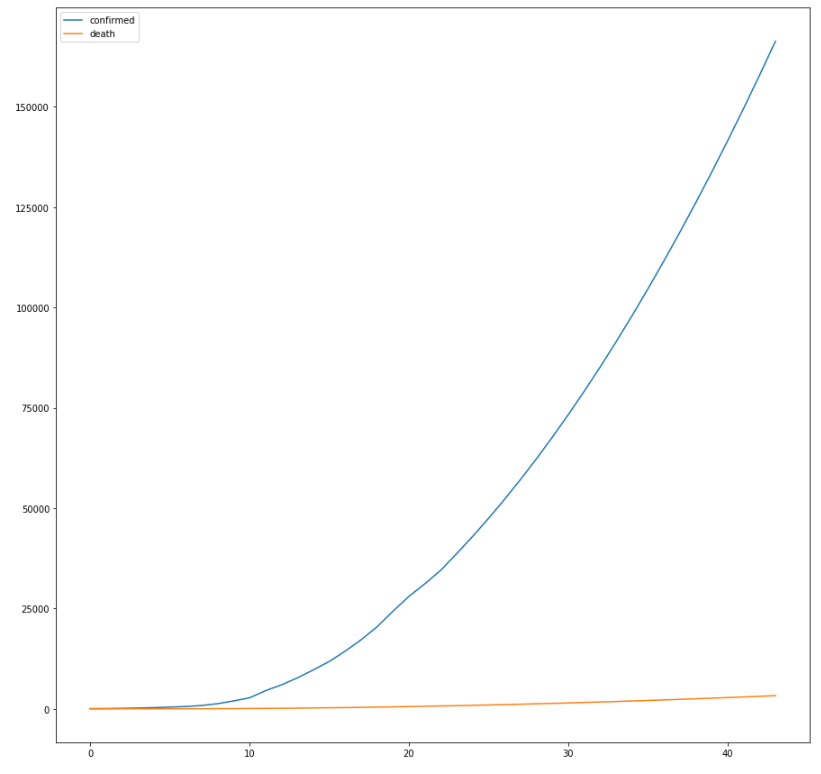
미래 구간 예측
현재의 데이터로 미래구간을 예측했을때는 다음과 같다. 제일 심플한 모델이지만 그럴듯한 2차함수식을 가지고 예측을 했을때는 y = 110×2 – 1147x 와 같은 2차식이 산출된다. 이제, 이러한 식으로 앞으로의 결과를 예측해볼수 있다.
| 일자 | 확진자수 | 사망자수 |
| 2020-02-08 | 38699 | 787 |
| 2020-02-09 | 42979 | 871 |
| 2020-02-10 | 47480 | 960 |
| 2020-02-11 | 52204 | 1053 |
| 2020-02-12 | 57148 | 1150 |
| 2020-02-13 | 62314 | 1252 |
| 2020-02-14 | 67702 | 1358 |
| 2020-02-15 | 73311 | 1468 |
| 2020-02-16 | 79142 | 1582 |
| 2020-02-17 | 85195 | 1701 |
| 2020-02-18 | 91468 | 1824 |
| 2020-02-19 | 97964 | 1951 |
| 2020-02-20 | 104681 | 2083 |
| 2020-02-21 | 111619 | 2218 |
| 2020-02-22 | 118779 | 2358 |
| 2020-02-23 | 126161 | 2503 |
| 2020-02-24 | 133764 | 2651 |
| 2020-02-25 | 141588 | 2804 |
| 2020-02-26 | 149634 | 2961 |
다만 중간에 확진자와 사망자가 꺾이기 시작하면, 이는 보통의 전염병과 같은 로지스틱 형태를 띄게 될것으로 예상되므로, 이는 대략 2월 중반정도가 되지 않을까 생각된다. 미래구간에 대한 시각화는 아래와 같다. 2월말에 누적 확진자가 15만명이 된다.
그래서 확진자수와 사망자수는 조작되었을 가능성이 있나?
- 중국의 발표된 확진자 수는 사실 얼핏 보기에도 너무나도 깨끗한 데이터이다. 그러나, 함수식에 끼워맞추는 식의 조작이라고 하기에는 지금 그래프도 충분히 나쁘다. 그 어떤 전염병보다도 빠르게 확산되고 있다. 즉 조작된 그래프도 별로 좋아보이지 않는다는 것이다.
- 사망자 수는 조작일까? 메르스는 그나마 소수 집중 치료가 들어간 우리나라에서조차 치사율이 20%가 넘었다. 신종 코로나는 홍콩 1명을 제외하고 사망자가 아직까지 나오지 않은것으로 보아 현재 발표된 중국내 치사율또한 인정할수는 있는 수치이다.
- 그래프가 뭔가 조작이 가해졌다면 증가하는 형식의 이차함수가 아니라, 보통의 전염병 처럼 점점 더 줄어들어 병세가 잡히는 모양의 그래프를 그렸지 않았을까?
- 시계열 누적그래프에 대해 R2만 따지면 0.90이상으로 피팅시키는것은 쉬운일이다.
- 너무나도 깨끗한 숫자가 나오는것은 확진자와 사망자수를 카운트하는 시스템 자체가 뭔가 규칙이 있거나 time dependent할 가능성이 있다. 혹은 아예 현재 확진자 수와 사망자수가 가늠이 되지 않는 상태이기 때문에 그럴듯한 값을 보고 하는것일 가능성이 있다.
- 조작이 있었건 없었건, 조작을 하더라도 저런 깨끗한 그래프를 만드는 방식보다는 일괄적으로 1/10씩 깎아 버려서 발표하는 방법을 쓰는게 훨씬 간편하고 좋은 생각일것 같다. 왜 굳이 모델을 만들어서 가상의 데이터처럼 보이게 만들까?